![[정보처리기사 실기] 2017년 3회 복원](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fp8H4n%2FbtrLipUJJys%2FKAj0krAc89kVHkupgnLbs1%2Fimg.png)
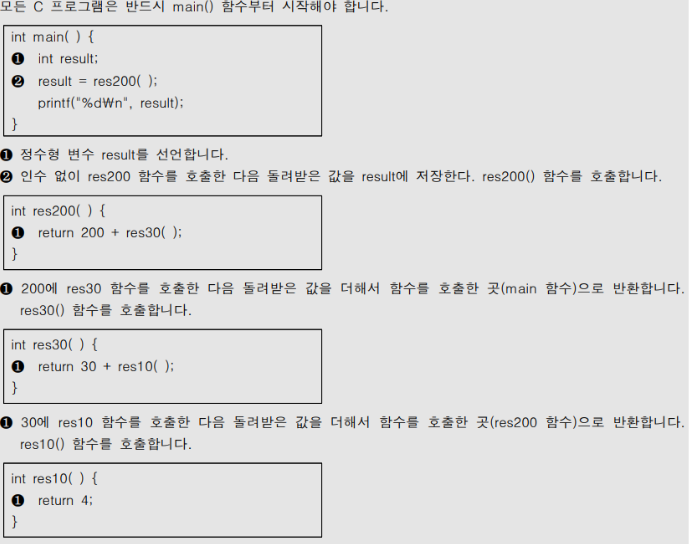
문제 1. 다음 C언어로 구현된 프로그램을 분석하여 그 실행 결과를 쓰시오. (3점)
#include <studio.h>
int res10() {
return 4;
}
int res30() {
return 30 + res10();
}
int res200() {
return 200 + res30();
}
int main() {
int result;
result = res200();
printf("%d\n", result);
}
답:
234

문제 2. 경영 혁신 기법 중 벤치마킹 기법의 개념을 간략히 서술하시오. (2점)
답:
특정 분야에서 우수한 상대를 모델로 하여 자기 기업과의 성과 차이를 비교 분석하고, 단점을 극복하기 위해 상대의 앞선 운영프로세스를 배우면서 꾸준히 노력하여 자기 혁신을 하는 경영기법이다.
문제 3. 데이터 마이닝의 개념과 데이터 마이닝의 기법 중 군집화의 개념을 서술하시오. (6점)
답:
데이터 마이닝의 개념: 데이터 웨어하우스에 저장된 데이터 집합에서 사용자의 요구에 따라 유용하고 가능성 있는 정보를 발견하기 위한 기법이다.
군집화의 개념: 상호 간에 유사한 특성을 갖는 데이터들을 집단화(Clustering)하는 방법이다.
<추가 정보>
데이터 마이닝이란 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 찾아내는 것이다.
데이터 마이닝의 절차는 다음과 같다.
데이터 추출 → 데이터 정제 → 데이터 변경 → 데이터 분석 → 데이터 해석 → 보고서 작성
데이터 마이닝의 기법
1) Association (연관성 탐색): 여러 트랜잭션간의 연관성 발견
2) Sequence (연속성 규칙): 트랜잭션의 순서에 따른 이력을 시계열적 분석하여 이후의 발생 가능성 예측
3) Classification (분류 규칙): 수집된 데이터의 패턴 및 속성으로 결합하여 트리 형태의 모델로 변형, 의사결정 및 예측
4) Clustering (데이터 군집화): 특징 및 속성의 유사성으로 데이터 그룹화
5) Characterization (특성 발견): 데이터의 특성에 따른 모델을 만들어 반복적인 학습 및 검증을 통한 특성 발견
문제 4. 다음은 배열에 저장된 5개의 자료 중 가장 큰 값과 가장 작은 값을 찾아 출력하는 프로그램을 Java 언어로 구현한 것이다. 프로그램을 분석하여 괄호에 해당하는 답안을 <답란>에 쓰시오. (5점)
<알고리즘의 이해>
최대값은 자료 중에서 가장 큰 값을 찾는 것이고 최소값은 자료 중에서 가장 작은 값을 찾는 것이다. 최대값을 찾는 방법 중 한 가지는 첫 번째 자료를 가장 작은 값으로 정하고 두 번째 자료부터 차례대로 비교하여 더 큰 값이 나오면 그 값을 최대값으로 하고 다음 자료와 비교하는 과정을 모든 자료에 대해 반복하는 것이다. 최소값을 찾는 방법 중 한 가지는 첫 번째 자료를 가장 큰 값으로 정하고 두 번째 자료부터 차례대로 비교하여 더 작은 값이 나오면 그 값을 최소값으로 하고 다음 자료와 비교하는 과정을 모든 자료에 대해 반복하는 것이다.
public class Test02{
public static void main(String[] args) {
int a[] = {10, 30, 50, 70, 90};
int i, max, min;
max = a[0];
min = a[0];
for(i = 0; i < 5; i++) {
if(( ) > max)
max = a[i];
if(( ) < min)
min = a[i];
}
System.out.printf("%d\n", max);
System.out.printgf("%d\n", min);
}
}
답:
a[i]

문제 5. 다음 신기술 동향과 관련된 설명에 가장 부합하는 용어를 쓰시오. (5점)
RADIUS(Remote Authentication Dial In User Service) 데이터를 전송 제어 프로토콜(TCP)이나 전송 계층 보안(TLS)을 이용하여 전송하기 위한 프로토콜이다. RADIUS over TLS'의 준말로, RADIUS는 이용자가 접속을 요구할 때 이용자의 ID나 암호와 같은 정보를 서버로 보내어 식별하고 인증을 수행한다. 하지만 기존의 RADIUS가 보안이 취약한 사용자 데이터그램 프로토콜(UDP)에 의존한다는 점와 패킷 적재 부분에서의 보안 취약성을 보완하기 위해 등장하였다. 보안성이 높은 TCP나 TLS를 사용하고, 이용자의 서버 간의 인증서 교환 등을 통한 상호 인증 서비스를 제공한다.
답:
래드섹
또는
RadSec
또는
래드섹 프로토콜
또는
RadSec Protocol
문제 6. 다음 신기술 동향과 관련된 설명 중 괄호 ( ) 안에 공통적으로 들어갈 가장 부합하는 용어를 쓰시오. (5점)
P2P 네트워크를 이용하여 온라인 금융 거래 정보를 온라인 네트워크 참여자(peer)의 디지털 장비에 분산 저장하는 기술을 의미한다. P2P 네트워크 환경을 기반으로 일정 시간 동안 반수 이상의 디지털 장비에 저장된 거래 내역을 서로 교환, 확인, 승인하는 과정을 거쳐서 디지털 서명으로 동의한 금융 거래 내역만 하나의 블록으로 만든다. 이렇게 생성된 블록은 기존의 ( )에 연결되고, 다시 복사되어 각 사용자의 디지털 장비에 분산 저장된다. 이로 인해 ( )은 기존 금융 회사들이 사용하고 있는 중앙 집중형 서버에 거래 정보를 저장할 필요가 없어 관리 비용이 절감되고, 분산 저장으로 인해 해킹이 난해해짐에 따라 보안 및 거래 안전성도 향상된다. 비트 코인(Bitcoin)이 ( )의 가장 대표적인 예이며, 주식, 부동산 거래 등 다양한 금융 거래에 사용이 가능하고 현관 키 등의 보안과 관련된 분야에도 활용될 수 있어 크게 주목받고 있다.
답:
블록체인
또는
Blockchain문제 7. 병행 제어의 개념과 병행 제어 기법 중 로킹 기법의 개념을 서술하시오. (4점)
답:
- 병행 제어의 개념: 다중 프로그램의 이점을 활용하여 동시에 여러 개의 트랜잭션을 병행 수행 할 때 실행되는 트랜잭션들이 데이터베이스의 일관성을 파괴하지 않도록 트랜잭션 간의 상호 작용 제어하는 기술이다.
- 로킹 기법의 개념: 주요 데이터의 액세스를 상호배타적으로 하는 것으로, 트랜잭션들이 어떤 로킹 단위를 액세스하기 전에 Lock(잠금)을 요청해서 Lock이 허락되어야만 그 로킹 단위를 액세스할 수 있도록 하는 기법이다.
<추가 정보>
병행(Concurrency)은 매우 빠르게 여러 트랜잭션 사이를 이동하면서 조금씩 처리를 수행하는 방식이다.따라서 실제로는 한 번에 한 트랜잭션만 수행하지만 마치 동시에 여러 트랜잭션을 수행하는 것처럼 보이도록 하는 것이다.병행 제어(Concurrency Control)는 트랜잭션이 병행 수행될 때 트랜잭션이 데이터베이스의 일관성을 파괴하지 않고, 다른 트랜잭션에 영향을 주지 않도록 트랜잭션 간의 상호작용을 제어하는 것을 말한다.
병행 제어의 목적
1) 데이터베이스의 일관성 유지
2) 데이터베이스 공유 최대화
3) 시스템 활용도 최대화
4) 사용자 응답 시간 최소화
5) 단위 시간당 트랜잭션 처리 건수 최대화
병행 제어를 하지 않을 시 문제점
1) 갱신 분실(Lost Update): 같은 데이터에 대해 둘 이상의 트랜잭션이 동시에 갱신할 때, 갱신 결과의 일부가 없어지는 현상
2) 모순성(Inconsistency): 하나의 트랜잭션이 여러 데이터 갱신 연산을 수행할 때, 일관성 없는 상태의 데이터베이스에서 데이터를 가지고 옴으로써 데이터의 불일치가 발생하는 것
3) 연쇄 복귀(Cascading Rollback): 병행 수행되던 둘 이상의 트랜잭션 중 어느 한 트랜잭션에 오류가 발생하여 Rollback 하는 경우 다른 트랜잭션들도 함께 Rollback되는 현상
4) 비완료 의존성(Uncommitted Dependency): 하나의 트랜잭션 수행이 실패한 후 회복하기 전에 다른 트랜잭션이 실패한 갱신 결과를 참조하는 현상
병행 제어 기법
1) 로킹(Locking): 트랜잭션이 접근하려는 데이터에 다른 트랜잭션이 접근하지 못하도록 잠그는(lock) 병행 제어 기법
이를 통해 상호 배제(Mutual Exclusive) 기능을 제공하며 잠금을 설정한 트랜잭션이 해제(unlock)할 때까지 데이터를 독점적으로 사용할 수 있음
👉🏻 한 번에 로킹할 수 있는 데이터의 크기를 로킹 단위라고 함
로킹 단위가 클수록 병행 제어 단순화, 관리 간편한 대신 병행성 수준이 낮아짐
로킹 단위가 작을수록 병행 제어가 복잡해지고, 오버헤드가 증가하지만 병행성 수준이 높아지고 데이터베이스 공유도가 높아짐
단점: 교착 상태(Dead lock: 여러 트랜잭션이 특정 데이터에 lock을 한 채 다른 트랜잭션이 lock을 수행한 데이터에 접근하려고 할 때 실행을 하지 못하고 서로 무한정 기다리는 상태)가 발생할 수 있음
2) 2단계 로킹 규약(Two-Phase Locking, 2PL): 각 트랜잭션의 lock과 unlock 요청을 2단계로 실시하는 방식
- 확장 단계(Growing phase): 새로운 lock 연산만을 수행할 수 있고, unlock 연산은 수행할 수 없는 단계
- 축소 단계(shrinking phase): unlock 연산을 수행할 수 있고, lock 연산은 수행할 수 없는 단계
👉🏻 트랜잭션 내의 모든 lock 연산이 첫 번째 unlock 연산 이전에 위치해야 함 (직렬성 보장)
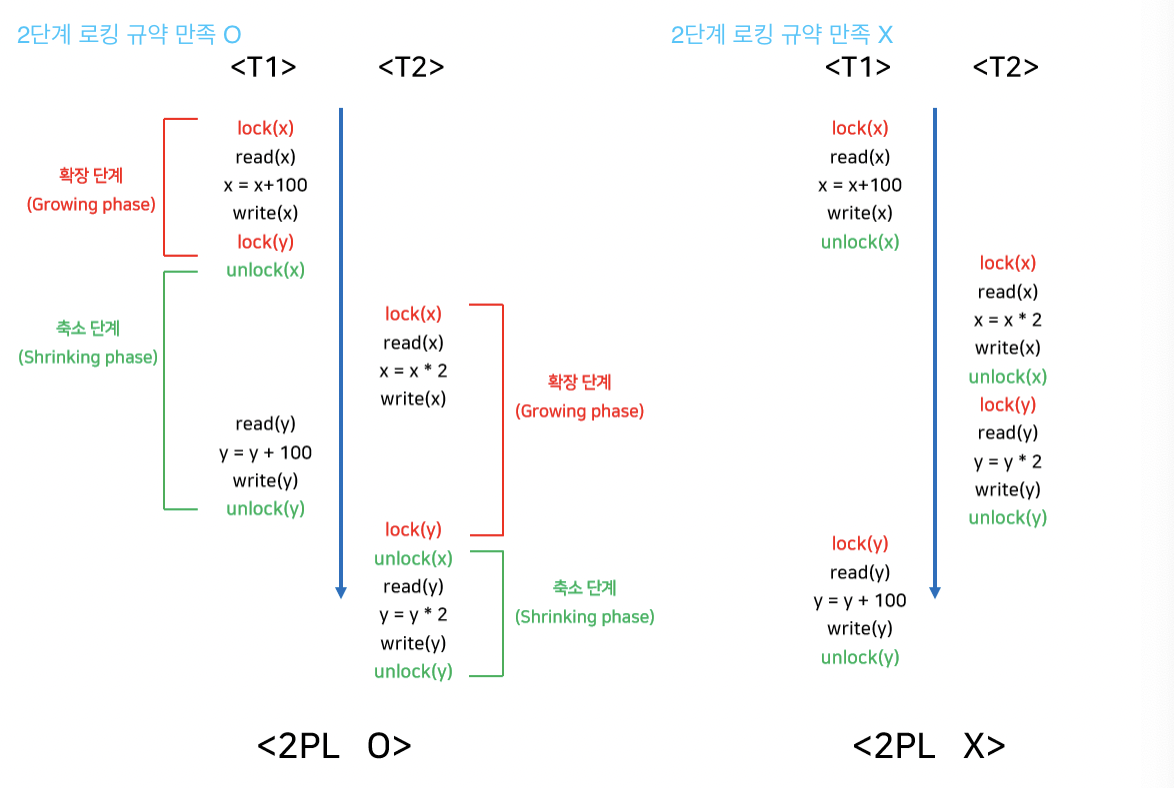
3) 타임 스탬프 순서(Timestamp ordering) 기법: 비직렬 트랜잭션을 타임 스탬프 순서에 따라 직렬화시키는 방법
장점: 데이터에 접근하는 시간(Timestamp)를 미리 정해 두어 부여된 시간 순서대로 데이터에 접근하며, lock을 사용하지 않고 시간을 나눠 사용하기 때문에 교착 상태(Dead lock)가 발생하지 않음
단점: Rollback 발생률이 높고 연쇄 복귀를 초래할 수 있음
4) 낙관적 병행 제어(Optimistric Concurrency Control): 트랜잭션 수행 동안은 어떠한 검사를 하지 않고 트랜잭션이 종료된 이후에 일괄적으로 검사하는 방식
👉🏻 수행 도중에는 트랜잭션을 위해 유지되는 데이터 항목들의 지역 사본에 대해서만 갱신하고, 트랜잭션 종료 후에 직렬화를 검증하여 데이터베이스에 한 번에 반영함
👉🏻 read-only(판독 전용)인 경우 충돌률이 매우 낮아 병행 제어 기법을 사용하지 않고도 대부분 일관성을 유지한다는 점을 이용한 방식임
5) 다중 버전 병행 제어(Multi-version Concurrency Control): 한 데이터에 여러 버전의 값을 유지하며 관리하는 방식
👉🏻 여러 버전의 타임 스탬프를 비교하여 스케줄상 직렬 가능성이 보장되는 타임 스탬프를 선택하므로 다중 버전 타임 스탬프 기법이라고도 함
👉🏻 충돌이 발생할 경우 연쇄 복귀가 발생할 수 있다는 단점이 있음
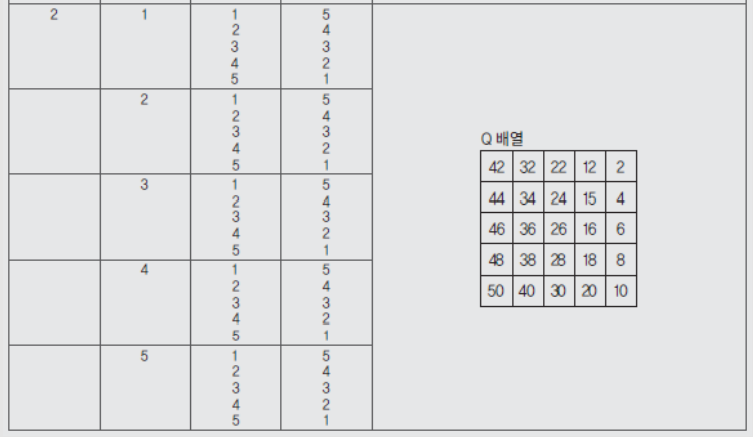
문제 8. 5행 5열의 배열에 P의 값을 저장한 후 <처리 조건> ①번과 같은 과정으로 두 번 90도 회전하여 결과를 다시 배열 P에 이동하는 알고리즘을 기술한 것이다. 알고리즘이 <처리 조건>에 따라 처리될 수 있는 가장 효율적인 알고리즘으로 구현될 수 있는 가장 효율적인 알고리즘으로 구현될 수 있도록 괄호 (①), (②), (③)에 해당하는 답안을 각각 <답란>에 쓰시오. (12점)

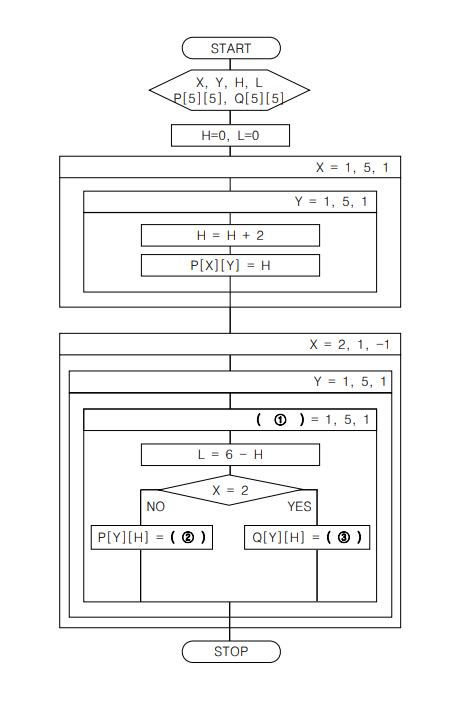
답:
① H
② Q[L], [Y]
③ P[L], [Y]

문제 9. 관계대수에서 사용되는 순수 관계 연산자 중 DIVISION에 대한 설명이다. 다음 괄호 ( ) 안에 들어갈 알맞은 기호를 쓰시오. (2점)
두 릴레이션 R(X)와 S(Y)에 대해 Y ⊆ X이고, X - Y = Z라고 하면, R(X)와 R(Z,Y)는 동일한 표현이다. 이때, 릴레이션 R(Z,Y)에 대한 S(Y)의 DIVISION 연산은 S(Y) 의 모든 튜플에 연관되어 있는 R(Z) 튜플을 선택하는 것으로 다음과 같이 표기한다.
[표기 형식]
R[속성r ( ) 속성s]S
답:
÷
<추가 정보>
관계 데이터 모델에서의 릴레이션을 조작하기 위한 기본 연산에는 관계대수와 관계해석이 있다.
관계대수: 원하는 목표 데이터를 얻기 위해 어떻게(how) 해야 되는지의 일련의 연산을 순서적으로 명세
관계해석: 무슨(what) 데이터를 원하는지만 선언
관계대수
1) 수학적 집합 이론으로부터의 일반 집합 연산(set operations) - 차수가 같아야 하고, 대응 애트리뷰드별 도메인이 같아야 함
1-1) 합집합(union, ∪): 두 릴레이션 R 또는 릴레이션 S에 속하는 튜플 t로 구성되는 릴레이션 (= or)
1-2) 교집합(intersection, ∩): 두 릴레이션 R과 S에 공통인 튜플 t로만 구성된 릴레이션 (= and)
1-3) 차집합(difference, -): 두 릴레이션 중 릴레이션 R에는 있지만 릴레이션 S에는 없는 튜플 t로만 구성된 릴레이션
1-4) 카티션 프로덕트(cartesian product, x): 두 릴레이션 중 R에 속한 각 튜플 t에 대해 릴레이션 S에 속한 각 튜플 s를 모두 접속(concatenation)시킨 튜플 r*s로 구성된 릴레이션
2) 관계 데이터베이스에 적용할 수 있도록 특별히 개발한 순수 관계 연산(relational operations)
2-1) 셀렉트(select, σ(시그마)): 릴레이션에 주어진 조건을 만족하는 튜플들을 선택하는 연산,
주어진 릴레이션을 수평적으로 절단하여 수평적 부분 집합(horizontal subset)을 생성함
2-2) 프로젝트(project, π(파이)): 릴레이션의 애트리뷰트를 연산 대상으로함
릴레이션을 수직적으로 절단한 열(column) 의 집합,
튜플이 중복되게 포함되면, 시스템은 그 중 하나만 제외 후 모두 제거함
2-3) 조인(join, ⋈): 릴레이션 R의 튜플 r과 릴레이션 S의 튜플 s에 대해 조건을 만족하는
모든 r와 s를 접속해서 만들어지는 튜플로 릴레이션을 새로 구성한 것
2-4) 디비전(division, ÷): 두 릴레이션 R(X)와 S(Y)에 대해 Y ⊆ X이고, X - Y = Z라고 하면, R(X)와 R(Z,Y)는 동일한 표현
문제 10. 다음 C언어로 구현된 프로그램을 분석하여 그 실행 결과를 쓰시오. (5점)
#include <studio.h>
int power(int data, int exp) {
int i, result = 1;
for(i = 0; i < exp; i++)
result = result * data;
return result;
}
int main() {
printf("%d\n", power(2, 10));
return 0;
}
답:
1024


문제 11. 데이터베이스와 관련한 다음 <처리 조건>에 부합하도록 괄호 (①) ~ (④)를 채워 SQL문을 완성하시오. (10점)
<처리 조건>
1. 이름, 학번, 전공, 성별, 생년월일로 구성된 <학생> 테이블을 정의하는 SQL문을 작성하시오.
단, 제약 조건은 다음과 같다.
- 이름은 NULL이 올 수 없고, 학번은 기본키다.
- 전공은 <학과> 테이블의 학과코드를 참조하는 외래키로 사용된다.
- <학과> 테이블에서 삭제가 일어나면 관련된 튜플들의 전공 값을 NULL로 만든다.
- <학과> 테이블에서 학과 코드가 변경되면 전공 값도 같은 값으로 변경한다.
- 생년월일은 1980-01-01 이후의 데이터만 저장할 수 있다.
- 제약조건의 이름은 '생년월일제약'으로 한다.
- 각 속성의 데이터형은 적당하게 지정한다. 단 성별은 도메인 'SEX'를 사용한다.
2. SQL문의 문법은 ISO/IEC 9075 표준을 따른다.
<SQL문>
CREATE TABLE 학생
(이름 VARCHAR(15) ( ① ),
학번 CHAR(8),
전공 CHAR(5),
성별 SEX,
생년월일 DATE,
( ② ) KEY(학번),
( ③ ) KEY(전공), ( ④ ) 학과(학과코드)
ON DELETE SET NULL,
ON UPDATE CASCADE,
CONSTRAINT 생년월일제약
CHECK(생년월일 >= '1980-01-01'));
답:
① NOT NULL
② PRIMARY
③ FOREIGN
④ REFERENCES
문제 12. 업무 프로세스와 관련한 다음의 <실무 사례>를 분석하여 각 문제의 물음 (①) ~ (③)에 답하시오. (10점)
<실무 사례>
(①)은 컴퓨터가 사람을 대신하여 정보를 읽고 이해하고 가공하여 새로운 정보를 만들어 낼 수 있도록 이해하기 쉬운 의미를 가진 차세대 지능형 웹이다. 예를 들면, 휴가 계획을 짜기 위하여 웹상에 있는 여행 정보를 일일이 직접 찾아서 비행기와 호텔을 예약하는 대신에 자동화된 프로그램에 대략적 휴가 일정과 개인의 선호도만을 알려 주면 자료의 의미가 포함되어 있는 웹상의 정보를 해독하여 손쉽게 세부 일정과 여행에 필요한 예약이 이루어지는 것과 같은 원리이다. (①)을 구성하는 핵심 기술로는 웹 자원(Resource)을 서술하기 위한 자원 서술 기술, 온톨로지(Ontology)를 통한 지식 서술 기술, 통합적으로 운영하기 위한 에이전트(Agent) 기술들을 들 수 있다.
-중략-
(②)은 기업에서 업무 처리를 할 때 다양하게 발생하는 거래 자료를 전산화해서 신속하고 정확하게 처리하는 정보화 시스템이다. 판매, 구매, 급여, 인사, 온라인 입출금 같은 빈번하게 발생하는 업무 자료를 거래 발생 즉시 처리하여 업무 효율을 증대시킨다.
-중략
(③)는 1985년 미국 국방부에서 컴퓨터를 이용해 군수 물자와 기술의 흐름을 합리적으로 통제하여 군수품 납품 체계를 개선할 목적으로 처음 도입되었다. (③)는 제품의 조달에서 설계, 개발, 생산, 운용, 유지보수에 이르는 제품의 수명 주기 전반에 대해 서류, 도면, 거래 등 모든 기술 정보 등을 통합 데이터베이스로 관리한다. (③)는 이후 전자상거래로 개념이 확대되어 오늘에 이르고 있다.
답: 각 문항별로 제시된 답안 중 한 가지만 쓰면 됨
(①) Semantic Web, 시맨틱 웹
(②) TPS, Transaction Processing System, 거래 처리 시스템
(③) CALS, Commerce At Light Speed, 광속 상거래
문제 13. 데이터베이스와 관련된 용어 중 하나인 비정규화의 개념을 서술하시오. (3점)
답:
비정규화의 개념: 정규화로 인해 여러 개로 분해된 릴레이션들에서 원하는 정보를 얻기 위해서는 조인을 사용하여 다시 연결해야 하는데, 지나치게 자주 조인을 사용하면 응답 속도가 떨어지므로 정규화에 위배되지만 성능 향상을 위해서는 다시 테이블을 합쳐야 한다. 이것을 비정규화라고 한다.
<추가 정보>
정규화 데이터베이스(normalized database): 중복을 최소화하도록 설계된 데이터베이스
장점👉🏻 데이터베이스 변경 시 이상 현상 제거, 저장 공간의 최소화, 효과적인 검색 알고리즘, 데이터 삽입 시 릴레이션 재구성 필요성 감소, 데이터 구조의 안정성 및 무결성 유지
단점👉🏻 상당수의 일상적 질의를 처리하기 위해 join을 많이 하게 되는 단점 -> 질의에 대한 응답 시간 저하
비정규화 데이터베이스(denormalized database): 시스템의 성능 향상, 개발 및 운영의 편의성을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배하는 (읽는 시간을 최적화하도록 설계된) 데이터베이스
장점👉🏻 join의 연산 비용을 줄일 수 있음, 테이블의 수가 줄어 조회 쿼리가 간단해짐, 높은 규모의 확장성
단점👉🏻 데이터 갱신/삽입 비용이 높음, 갱신/삽입 코드 작성의 어려움, 데이터의 일관성 깨짐, 데이터 중복 저장으로 공간 필요
문제 14. 신기술 동향과 관련한 다음의 <실무 사례>를 분석하여 각 문제의 물음 (①) ~ (③)에 한글로 답하시오. (10점)
<실무 사례>
(①)이란 컴퓨터 보안에 있어서, 인간 상호 작용의 깊은 신뢰를 바탕으로 사람들을 속여 정상 보안 절차를 깨트리기 위한 비기술적 시스템 침입 수단을 말한다. 우선 통신망 보안 정보에 접근 권한이 있는 담당자와 신뢰를 쌓고 전화나 이메일을 통해 그들의 약점과 도움을 이용하는 것이다. 상대방의 자만심이나 권한을 이용하는 것, 정보의 가치를 몰라서 보안을 소홀히 하는 무능에 의존하는 것과 도청 등이 일반적인 (①)적 공격 전략이다.
-중략-
(②)기법은 장기간 보관하여 두고 조금씩 얇게 썰어서 먹는 이탈리아 소시지에서 따온 말로, 많은 대상으로부터 눈치 채지 못할 만큼의 적은 금액이나 양을 빼내는 컴퓨터 사기 기법을 말한다.
-중략
(③)는 수집된 후 저장은 되어 있지만 분석에 활용되지는 않는 다량의 데이터를 의미한다. (③)는 향후 사용될 가능성이 있다는 이유로 삭제되지 않아 공간만 차지하고 있으며, 보안 위협을 초래하기도 한다.
답:
(①) 사회 공학
(②) 살라미
(③) 다크 데이터
문제 15. 신기술 동향과 관련한 설명 중 괄호 ( ) 안에 공통적으로 들어갈 가장 부합하는 용어를 쓰시오. (5점)
( )은(는) 네트워크를 컴퓨터처럼 모델링하여 여러 사용자가 각각의 소프트웨어 프로그램들로 네트워킹을 가상화하여 제어하고 관리하는 네트워크이다. ( ) 기술은 네트워크 비용 및 복잡성을 해결할 수 있는 기술로 간주되어 기존 네트워킹 기술의 폐쇄형 하드웨어 및 소프트웨어 기술을 개방형으로 변화시키는 미래 인터넷 기술로 떠오르고 있다.
답: 다음 중 한 가지만 쓰면 됩니다.
SDN
또는
Software Defined Networking
또는
소프트웨어 정의 네트워킹
문제 16. 다음 업무 프로세스와 관련된 설명 중 괄호 ( ) 안에 공통적으로 들어갈 가장 부합하는 용어를 쓰시오. (3점)
( )은(는) 웹 서비스와 관련된 서식이나 프로토콜 등을 표준적인 방법으로 기술하고 게시하기 위한 언어로, SOAP 툴킷에 웹 서비스를 기술하기 위해 개발되었다. 웹 서비스가 확장성 생성 언어(XML)를 기반으로 하여 표현되고 ( )로 정의되면, UDDI(Universal Descreption, Discovery, and Integration)에 의해 서비스 저장소에 등록된다. 이후 등록된 서비스는 웹에 접속하는 누구라도 찾아 사용할 수 있도록 공개된다. 웹 서비스는 ( )에 의해 서비스 제공 장소나 서비스 메시지 포맷, 프로토콜 등의 구체적인 내용이 기술된다.
답:
웹 서비스 기술 언어
또는
WSDL
또는
Web Service Description Language
문제 17. 다음 전산영어와 관련한 다음 설명의 괄호 (①), (②), (③)에 가장 부합하는 답안을 영문 Full-name으로 쓰시오. (10점)
MMS is a standard way to send messages that include (①) content to and from a mobile phone over a cellular network. The MMS standard extends the SMS(Short Message Service) capability, allowing the exchange of (②) messages greater than 160 characters in length. Unlike (②)-only SMS, MMS can deliver a variety of media including up to forty seconds of video, one (③), a dlideshow of multiple (③)s, or audio.
답:
(①): multimeida
(②): text
(③): image
[원문 해석]
MMS는 셀룰러 네트워크를 통해 핸드폰으로 또는 핸드폰으로부터 ( 멀티미디어 ) 콘텐츠가 포함된 메시지를 보내는 표준적인 방법이다. MMS 표준은 SMS(Short Message Service) 기능을 확장하여, 160자 이상의 ( 문자 ) 메시지를 교환할 수 있도록 한다. ( 텍스트 ) 적용 SMS와 달리, MMS는 최대 40초 분량의 비디오, 하나의 ( 이미지), 여러 ( 이미지) 들의 슬라이드 쇼 또는 오디오를 포함한 다양한 미디어를 전달할 수 있다.