![[정보처리기사 정리 요약본] 2과목. 소프트웨어 개발](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbl5Ljf%2FbtrFe4aj1OW%2FFAqS62fnB9s6hmwhIUYvWk%2Fimg.png)
2과목. 소프트웨어 개발
1장. 데이터 입출력 구현
036.자료 구조(B) 그림으로 같이 확인 할 것
효율적 프로그램을 작성할 때 가장 우선적인 고려사항은 저장 공간의 효율성과 실행시간의 신속성
자료 구조는 일련의 자료들을 조직하고 구조화함
어떠한 자료 구조에서도 필요한 모든 연산을 처리할 수 있음
자료 구조에 따라 프로그램 실행 시간이 달라짐
선형 구조(Linear Structure)
- 배열(Array): 첨자를 이용한 데이터 접근법
동일한 자료형의 데이터들이 같은 크기로 나열되어 순서를 갖고 있는 집합
정적인 자료 구조로 기억장소의 추가가 어렵고 데이터 삭제 시 데이터가 저장되어 있던
기억장소가 빈 공간으로 남아 있어 메모리의 낭비 발생
반복적인 데이터 처리 작업에 적합
동일한 이름의 변수를 사용하여 처리 간편
사용한 첨자의 개수에 따라 n차원 배열이라고 함
- 선형 리스트(Linear List): 일정한 순서에 의해 나열된 자료 구조
(1) 연속 리스트(Contiguous List): 배열을 이용하여 연속되는 기억장소에 저장됨
기억장소를 연속적으로 배정받기 때문에 기억장소 이용 효율은 밀도 1로 가장 good
중간에 데이터 삽입을 위해서는 연속된 빈 공간이 있어야 함
삽입과 삭제 시 자료의 이동이 필요함
(2) 연결 리스트(Linked List): 포인터(링크)를 이용
자료를 반드시 연속적으로 배열시키는 게 아닌 임의의 기억공간에 기억시킴
자료 항목의 순서에 따라 노드(데이터+링크)의 포인터(링크) 부분을 이용해 서로 연결시킴
노드의 삽입/삭제 작업이 용이
기억 공간이 연속적으로 놓여 있지 않아도 저장 가능
포인터(링크) 부분이 필요하기 때문에 연속 리스트보다 기억 공간의 이용 효율 낮음
연결을 위한 포인터를 찾는 시간 때문에 접근 속도가 느림
중간 노드 연결이 끊어지면 다음 노드를 찾기 힘듦
- 스택(Stack): 리스트의 한쪽 끝으로만 자료의 삽입/삭제 작업이 이루어짐
가장 나중에 삽입된 자료가 가장 먼저 삭제되는 후입선출(LIFO) 방식으로 자료 처리
모든 기억 공간이 꽉 찬 상태에서 데이터 삽입 시 오버플로(Overflow)
더 이상 삭제할 데이터가 없는 상태에서 데이터를 삭제하면 언더플로(Underflow) 발생
TOP: 가장 마지막으로 삽입된 자료 / Bottom: 스택의 가장 밑바닥
- 큐(Queue): 리스트의 한쪽에서는 삽입, 다른 한쪽에서는 삭제 작업이 이루어짐
운영체제의 작업 스케줄링에 사용됨
가장 먼저 삽입된 자료가 가장 먼저 삭제되는 선입선출(FIFO) 방식으로 자료 처리
시작과 끝을 표시하는 두 개의 포인터가 있음
프런트(F, Front) 포인터: 가장 먼저 삽입된 자료의 기억 공간을 가리킴
리어(R, Rear) 포인터: 가장 마지막에 삽입된 자료의 기억 공간을 가리킴
- 데크(Deque)
비선형 구조(Non-Linear Structure)
- 트리(Tree): 사이클이 없는 그래프
- 그래프(Graph): 정점 V(Vertex)와 간선 E(Edge)의 두 집합으로 이루어짐
간선의 방향성 유무에 따라 방향 그래프와 무방향 그래프로 구분됨
방향/무방향 그래프의 최대 간선 수: 무방향일 때 n(n-1)/2개, 방향 그래프일 때 n(n-1)개
ex) 정점(노드)이 4개인 경우,
- 무방향 그래프의 최대 간선 수: 4(4-1)/2 = 6개
- 방향 그래프의 최대 간선 수: 4(4-1) = 12개
037. 트리(Tree)(A)
정점(Node, 노드)와 선분(Branch, 가지)를 이용해 사이클을 이루지 않도록 구성한 특수 그래프
트리 관련 용어(트리 그림 참조하여 확인하기)
노드(Node): 트리의 기본 요소로 자료 항목과 다른 항목에 대한 가지(Branch)를 합친 것
근 노드(Root Node): 트리의 맨 위에 있는 노드
디그리(Degree, 차수): 각 노드에서 뻗어 나온 가지의 수
단말 노드(Terminal Node) = 잎 노드(Leaf Node): 자식이 하나도 없는 노드, 즉 디그리 0인 노드
자식 노드(Son Node): 어떤 노드에 연결된 다음 레벨의 노드들
부모 노드(Parent Node): 어떤 노드에 연결된 이전 레벨의 노드들
형제 노드(Brother Node, Sibling) 동일한 부모를 갖는 노드들
트리의 디그리: 노드들의 디그리 중에서 가장 많은 수
트리의 운행법: 트리를 구성하는 각 노드들을 찾아가는 방법
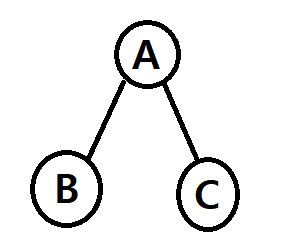
Preorder 운행: Root - Left - Right
Inorder 운행: Left - Root - Right
Postorder 운행: Left - Right - Root
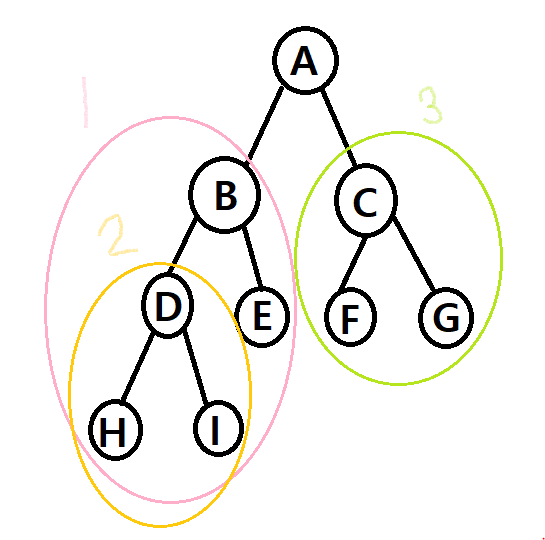
Preorder 운행법 방문 순서: Root - Left - Right이므로 A13 -> AB2E3 -> ABDHIECFG
Inorder 운행법 방문 순서: Left - Root - Right이므로 1A3 -> 2BEA3 -> HDIBEAFCG
Postorder 운행법 방문 순서: Left - Right - Root이므로 13A -> 2EB3A -> HIDEBFGCA
수식의 표기법: 산술식을 계산하기 위해 기억공간에 기억시키는 방법
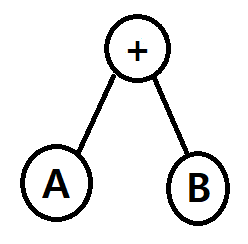
전위 표기법(PreFix): 연산자 - Left - Right, +AB
중위 표기법(InFix): Left - 연산자 - Right, A+B
후위 표기법(PostFix): Left - Right - 연산자, AB+
- 중위(Infix) 표기를 전위(Prefix) 표기나 후위(PostFix) 표기로 바꾸는 법
연산 우선순위에 따라 괄호로 묶은 뒤,
PreFix의 경우 연산자를 괄호 앞, PostFix는 연산자를 괄호 뒤로 보내기
예시) X = A / B * ( C + D ) + E
연산 우선순위에 따라 괄호로 묶기: (X = (((A / B) * ( C + D )) + E))
PreFix로 변환, 연산자를 괄호 앞: = X + * / A B + C D E
PostFix로 변환, 연산자를 괄호 뒤:X A B / C D + * E + =
- 후위(Postfix) 표기나 전위(PreFix) 표기된 수식을 중위(Infix) 표기로 바꾸는 법
인접한 피연산자 두 개 + 왼쪽(Prefix) 또는 오른쪽(PostFix) 연산자를 괄호로 묶은 뒤,
연산자를 해당 피연산자 사이로 이동시키고 필요 없는 괄호 제거
예시) A B C - / D E F + * +
Postfix 변환: 피연산, 피연산, 연산자를 괄호로 묶은 뒤 연산자를 피연산자 사이로 이동
A (B C -) / D (E F +) * +
→ (A (B C -) /) (D (E F +) *) +
→ ((A (B C -) /) (D (E F +) *) +)
변환 완료: A / ( B - C ) D + * ( E + F )
예시) + / A - B C * D + E F
Prefix 변환: 연산자, 피연산자, 피연산자를 괄호로 묶은 뒤 연산자를 피연산자 사이로 이동
+ / A - B C * D + E F
→ + / A (- B C) * D (+ E F)
→ + (/ A (- B C)) (* D (+ E F))
→ (+ (/ A (- B C)) (* D (+ E F)))
변환 완료: A / ( B - C ) + D * ( E + F )
038. 정렬(Sort) (A)
- 삽입 정렬(Insertion Sort): 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬함
1회전: 두 번째 키와 첫 번째 키 비교해 순서대로 나열
2회전: 세 번째 키를 첫 번째, 두 번째 키와 비교해 순서대로 나열
…
- 쉘 정렬(Shell Sort): 삽입 정렬을 확장한 개념으로 입력 파일을 매개변수(h) 값으로 서브 파일을 구성하고 각 서브파일을 Insertion 정렬 방식으로 순서 배열하는 과정 반복
입력 파일이 부분적으로 정렬되어 있는 경우에 유리
- 선택 정렬(Selection Sort): n개의 레코드 중에서 최소값을 찾아 첫 번째 레코드 위치에 놓고, 나머지 (n-1)개중에서 다시 최소값을 찾아 두 번째 레코드 위치에 놓는 방식을 반복하여 정렬
1회전: 첫 번째 레코드와 두 번째 레코드 비교하여 최소값 찾기,
첫 번째 레코드와 세 번째 레코드 비교하여 최소값 찾기…
2회전: 두 번째 레코드와 세 번째 레코드 비교하여 최소값 찾기,
두 번째 레코드와 네 번째 레코드 비교하여 최소값 찾기…
…
- 버블 정렬(Bubble Sort): 인접한 두 개의 레코드 키 값을 비교하여 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식
1회전: 첫 번째 레코드와 두 번째 레코드를 비교하여 최소값 찾기,
두 번째 레코드와 세 번째 레코드를 비교하여 최소값 찾기
…
n번째 레코드와 n-1번째 레코드를 비교하여 최소값 찾기
2회전: 첫 번째 레코드와 두 번째 레코드를 비교하여 최소값 찾기,
두 번째 레코드와 세 번째 레코드를 비교하여 최소값 찾기
…
n-1번째 레코드와 n-2번째 레코드를 비교하여 최소값 찾기
…
마지막 회전: 첫 번째 레코드와 두 번째 레코드를 비교하여 최소값 찾기
- 퀵 정렬(Quick Sort): 레코드의 많은 자료 이동을 없애고 하나의 파일을 부분적으로 나누어 가면서 정렬하는 방법으로 키를 기준으로 작은 값은 왼쪽에, 큰 값은 오른쪽 서브 파일로 분해
정렬 방식 중 가장 빠름
되부름을 이용하기 때문에 스택(Stack)이 필요함
분할(Divide)와 정복(Conquer)을 통해 자료 정렬
- 힙 정렬(Heap Sort): 전이진 트리(Complete Binary Tree, 차수가 모두 2개인 트리)를 이용
차수가 모두 2개인 트리로 변환 후 위에서부터 차례로 큰 순서대로 나열
- 2-way 합병 정렬(Merge Sort): 이미 정렬된 두 개의 파일을 한 개의 파일로 합병
1회전: 두 개씩 묶은 후 각각의 묶음 안에서 정렬
2회전: 묶여진 묶음을 두 개씩 다시 묶은 후 각각의 묶음 안에서 정렬
…
마지막 회전: 묶여진 두 개의 묶음을 하나로 묶은 후 정렬
- 기수 정렬(Radix Sort) = Bucket Sort
큐(Queue)를 이용하여 자릿수(Digit)별로 정렬하는 방식이며 키 값을 분석하여 같은 수 또는
같은 문자끼리 그 순서에 맞는 버킷에 분배하였다가 버킷의 순서대로 레코드를 꺼내어 정렬
039. 데이터베이스 개요 (A)
데이터 저장소: 데이터들을 논리적인 구조로 조직화하거나 물리적인 공간에 구축한 것을 의미
- 논리 데이터 저장소: 데이터 및 데이터 간의 연관성, 제약조건을 식별하여 논리적인 구조로 조직화
- 물리 데이터 저장소: 소프트웨어 운용될 환경의 물리적 특성을 고려하여 하드웨어적 저장장치에 저장
데이터베이스: 특정 조직의 업무 수행에 필요한 상호 관련된 데이터들의 모임
- 통합된 데이터(Integrated Data): 자료의 중복을 배제한 데이터 모임
- 저장된 데이터(Stored Data): 컴퓨터가 접근할 수 있는 저장 매체에 저장된 자료
- 운영 데이터(Operational Data): 업무 수행 시 존재 가치 확실하고 없어서는 안 될 반드시 필요한 자료
- 공용 데이터(Shared Data): 여러 응용 시스템들이 공동으로 소유하고 유지하는 자료
DBMS(DataBase Management System; 데이터베이스 관리 시스템)
기존의 파일 시스템이 갖는 데이터의 종속성과 중복성 문제를 해결하기 위해 제안된 시스템
DBMS의 필수 기능
- 정의(Definition): 데이터의 형과 구조에 대한 정의, 이용 방식, 제약 조건 등을 명시
- 조작(Manipulation): 사용자와 데이터베이스 사이의 인터페이스 수단을 제공하는 기능
- 제어(Control): 무결성, 권한 검사, 병행 제어
DBMS의 장단점
장점: 논리적, 물리적 독립성이 보장 / 중복 배제, 기억 공간 절약 / 일관성 / 무결성 / 보안 / 표준화 / 통합 관리 / 최신의 데이터 유지 / 실시간 처리
단점: 전문가 부족 / 전산화 비용 증가 / 대용량 디스크로의 집중적 에세스로 과부화 발생 / 예비(Backup), 회복 어려움 / 시스템 복잡
스키마: 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 메타 데이터의 집합
- 외부 스키마: 사용자나 응용 프로그래머가 개인 입장에서 필요로 하는 DB의 논리적 구조를 정의
- 개념 스키마: DB의 전체적인 논리적 구조로서 필요로 하는 데이터를 종합한 조직 전체의 데이터베이스로 하나만 존재함
- 내부 스키마: 물리적 저장장치의 입장에서 본 데이터베이스 구조로서 레코드의 형식을 정의하고 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 등을 나타냄
040. 데이터의 입출력(C)
SQL(Structured Query Language): 국제 표준 데이터베이스 언어로 관계형 데이터베이스를 지원하는 언어
관계대수(원하는 정보를 검색하기 위해 어떻게 유도하는가)와 관계해석(연산 표현법)을 기초로 한 혼합 데이터
프로그래밍 언어를 잘 모르는 사용자들이 단말기를 통해 대화식으로 쉽게 DB를 이용할 수 있도록 한 질의어이지만 질의 기능뿐 아니라 정의, 조작, 제어 기능을 모두 갖추고 있음
- 데이터 정의어(DDL; Data Define Language): SCHEMA, DOMAIN, TABLE, VIEW, INDEX를 정의하거나 변경 또는 삭제할 때 사용하는 언어
- 데이터 조작어(DML; Data Manipulation Language): 사용자가 응용 프로그램이나 질의어를 통하여 저장된 데이터를 실질적으로 처리하는 데 사용되는 언어
- 데이터 제어어(DCL; Data Control Language): 데이터 보안, 무결성, 회복, 병행 수행 제어 등을 정의
데이터 접속(Data Mapping): 프로그래밍 코드와 데이터베이스의 데이터를 연결하는 것
SQL Mapping: 프로그래밍 코드 내에 SQL을 직접 입력하여 데이터에 접속하는 기술로 관련 프레임워크로는 JDBC, ODBC, Mybatis 등이 있음
ORM(Object-Relational Mapping): 객체지향 프로그래밍의 객체(Object)와 관계형 데이터베이스의 데이터를 연결하는 기술로 관련 프레임워크에는 JPA, Hibernate, Django 등이 있음
트랜잭션(Transaction): 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 수행되어야 할 일련의 연산들
트랜잭션 제어 언어( TCL; Transaction Control Language) 종류
- COMMIT: 트랜잭션 처리가 정상적으로 종료되어 트랜잭션이 수행한 변경 내용을 데이터베이스에 반영하는 명령어
- ROLLBACK: 하나의 트랜잭션 처리가 비정상으로 종료되어 데이터베이스의 일관성이 깨졌을 때 트랜잭션이 행한 모든 변경 작업을 취소하고 이전 상태로 되돌리는 연산
- SAVEPOINT(=CHECKPOINT): 트랜잭션 내에 ROLLBACK 할 위치인 저장점을 지정하는 명령어이며 트랜잭션당 여러 개를 지정할 수 있음
041. 절차형 SQL (D)
연속적인 실행이나 분기, 반복 등의 제어가 가능한 SQL
일반적 프로그래밍 언어에 비해 효율은 떨어지지만 단일 SQL문장으로 처리하기 어려운 연속 작업 처리에 적합
DBMS 엔진에서 직접 실행되기 때문에 입출력 패킷이 적은 편
BEGIN ~ END 형식으로 작성되는 블록(Block) 구조로 되어 있기 때문에 기능별 모듈화가 가능
절차형 SQL의 종류
- 프로시저(Procedure): 특정 기능을 수행하는 일종의 트랜잭션 언어로 호출을 통해 실행되며 미리 저장해 놓은 SQL 작업을 수행
- 트리거(Trigger): 데이터베이스 시스템에서 데이터의 입력, 갱신, 삭제 등의 이벤트(Event)가 발생할 때마다 관련 작업이 자동으로 수행
- 사용자 정의 함수: 프로시저와 유사하게 SQL을 사용하여 일련의 작업을 연속적으로 처리하며, 종료 시 예약어 Return을 사용하여 처리 결과를 단일값으로 반환함
2장. 통합 구현
042.단위 모듈 구현(C)
소프트웨어 구현에 필요한 여러 동작 중 한 가지 동작을 수행하는 기능을 모듈로 구현한 것으로 단위 기능이라고도 부름
단위 기능 명세서 작성 —> 입출력 기능 구현 —> 알고리즘 구현
정보 은닉의 원리 고려 CLI, GUI 연동 고려
알고리즘 구현 모듈
- 디바이스 드라이버 모듈: 하드웨어 주변 장치의 동작을 구현한 모듈
- 네트워크 모듈: 네트워크 장비 및 데이터 통신을 위한 기능을 구현한 모듈
- 파일 모듈: 컴퓨터 내부의 데이터 구조 영역에 접근하는 방법을 구현한 모듈
- 메모리 모듈: 파일을 프로세스 가상 메모리에 매핑/해제하는 방법, 프로세스 사이 통신 기능 구현 모듈
- 프로세스 모듈: 하나의 프로세스 안에서 다른 프로세스를 생성하는 방법을 구현한 모듈
043. 단위 모듈 테스트(C)
프로그램의 단위 기능을 구현하는 모듈이 정해진 기능을 정확하게 수행하는지 검증하는 것으로 단위 테스트라고도 함
모듈을 단독적으로 실행할 수 있는 환경과 테스트에 필요한 데이터가 모두 준비되어야 함
모듈 통합 이후에는 오랜 시간 추적해야 발견할 수 있는 에러들도 단위 모듈 테스트 수행 시 쉽게 발견 가능
단위 모듈에 대한 코드이므로 시스템 수준의 오류는 잡아낼 수 없음
ISO/IEC/IEEE 29119-3 표준에 따른 테스트 케이스의 구성 요소
- 식별자(Identifier): 항목 식별자, 일련번호
- 테스트 항목(Test Item): 테스트 대상(모듈 또는 기능)
- 입력 명세(Input Specification): 입력 데이터 또는 테스트 조건
- 출력 명세(Output Specification): 테스트 케이스 수행 시 예상되는 출력 결과
(출력값 X / 예상 출력값 O)
- 환경 설정(Environmental Needs): 필요한 하드웨어나 소프트웨어의 환경
- 특수 절차 요구(Special Procedure Requirement): 테스트 케이스 수행 시 특별히 요구되는 절차
- 의존성 기술(Inter-case Dependency): 테스트 케이스 간의 의존성
044. 개발 지원 도구(C)
통합 개발 환경(IDE; Integrated Development Environment)
개발에 필요한 환경인 편집기, 컴파일러, 디버거 등 다양한 툴을 하나의 인터페이스로 통합하여 제공하는 것
빌드 도구
소스 코드 파일들을 컴퓨터에서 실행할 수 있는 제품 소프트웨어로 변환하는 과정 또는 결과물
Ant: 아파치, XML 기반의 빌드 스크립트 사용, 자유도와 유연성 높음
Maven: 아파치, Ant의 대안, 의존성(Dependency) 설정하여 라이브러리 관리
Gradle: Ant, Maven을 보완, 안드로이드 스튜디오 공식 빌드 도구, 그루비(Groovy) 기반의 빌드 스크립트
기타 협업 도구(=그룹웨어; Groupware)
개발에 참여하는 사람들이 서로 다른 작업 환경에서 원활히 프로젝트를 수행할 수 있도록 도와주는 도구
일정 관리, 업무 흐름 관리, 정보 공유, 커뮤니케이션 등 업무 보조 도구가 포함됨
웹 기반, PC, 스마트폰 등 다양한 플랫폼에서 사용할 수 있도록 제공됨
협업 도구가 익숙하지 않거나 이용할 의지가 없으면 오히려 협업의 방해 요소가 될 수 있음
3장. 제품 소프트웨어 패키징
045. 소프트웨어 패키징(A)
모듈별로 생성한 실행 파일들을 묶어 배포용 설치 파일을 만드는 것
개발자가 아닌 사용자 중심으로 진행
향후 관리를 위해 소스 코드는 모듈화하여 패키징함
사용자의 소프트웨어 환경을 고려하여 다양한 환경에서 사용할 수 있도록 일반적인 배포 형태로 패키징
패키징 시 고려사항
- 사용자의 시스템 환경인 운영체제, CPU, 메모리 등에 필요한 최소 환경을 정의함
- UI는사용자가 눈으로 직접 확인할 수 있도록 시각적인 자료와 함께 제공하고 매뉴얼과 일치시킴
- 하드웨어와 함께 관리될 수 있도록 Managed Service 형태로 제공하는 것이 좋음
- 사용자에게 배포되는 컨텐츠이므로 내부 콘텐츠에 대한 암호화 및 보완을 고려함
- 사용자 편의성을 위해 복잡성 및 비효율성 문제를 고려
- 제품 소프트웨어 종류에 적합한 암호화 알고리즘을 적용
패키징 작업 순서
기능 식별 —> 모듈화 —> 빌드 진행 —> 사용자 환경 분석 —> 패키징 및 적용 시험 —> 변경 개선 —> 배포
모듈화: 모듈 단위로 코드를 분류하는 것 (모듈 단위별로 실행 파일을 만드는 것 X)
046. 릴리즈 노트 작성(B)
개발 과정에서 정리된 릴리즈(배포) 정보를 소프트웨어의 최종 사용자인 고객과 공유하기 위한 문서
릴리즈 노트는 소프트웨어 초기 배포 시 또는 출시 후 개선사항을 적용한 추가 배포 시에 제공함
초기 배포 시 제공할 때는 소프트웨어에 포함된 기능, 사용 환경에 대한 내용을 확인해야 함
출시 후 개선된 작업이 있을 때마다 관련 내용을 릴리즈 노트에 담아 제공
철저한 테스트를 거치고 배포하며, 개발팀이 제공하는 소프트웨어 사양의 최종 승인 후 문서화되어 제공됨
릴리즈 노트 초기 버전 작성 시 고려사항
- 정확하고 완전한 정보를 기반으로 개발팀에서 직접 현재 시제로 작성해야 함
- 신규 소스, 빌드 등의 이력이 정확하게 관리되어 변경 및 개선된 항목에 대한 이력 정보가 작성돼야 함
- 표준 형식은 없으나 머릿말, 개요, 목적, 문제 요약, 재현 항목, 수정 내용, 사용자 영향도, 노트, 면책 조항 등이 기재되어야 함
릴리즈 노트 추가 버전 작성 시 고려사항
- 소프트웨어의 테스트 과정에서 베타 버전이 출시되거나 긴급한 버그 수정, 업그레이드, 사용자 요청이 발생하는 경우 추가 작성함
- 중대한 오류 발생 시: 릴리즈 버전 출시하고 버그 번호 포함 모든 수정 내용을 작성
- 기능 업그레이드를 완료한 경우: 릴리즈 버전 출시하고 작성
- 사용자로부터 접수된 요구사항에 의한 수정: 별도의 릴리즈 버전 출시하고 작성
작성 순서
모듈 식별 —> 릴리즈 정보 확인 —> 릴리즈 노트 개요 작성 —> 영향도 체크 —> 정식 릴리즈 노트 작성 —> 추가 개선 항목 식별
047. 디지털 저작권 관리(DRM) (A)
소설, 시, 논문, 강연, 컴퓨터 프로그램 저작물 등에 대하여 창작자가 가지는 배타적 독점적 권리로 타인의 침해를 받지 않을 고유 권한
원본 콘텐츠가 아날로그일 경우 디지털로 변환 후 패키저에 의해 DRM 패키징 수행
크기가 작다면, 사용자의 요청 시점에 실시간 패키징 수행
크기가 크다면, 미리 패키징 수행 후 배포
패키징을 수행하면 콘텐츠에 암호화된 저작권자의 전자서명이 포함되고 저작권자가 설정한 라이선스 정보가 클리어링 하우스에 등록됨
종량제 방식 소프트웨어의 경우, 클리어링 하우스를 통해 서비스의 실제 사용량 측정 후 이용한 만큼 요금 부과
디지털 저작권 관리의 흐름 및 구성 요소
클리어링 하우스(Clearing House): 저작권에 대한 사용 권한, 라이선스 발급, 암호화된 키 관리, 사용량에 따른 결제 관리 등을 수행하는 곳
콘텐츠 제공자(Contents Provider): 콘텐츠를 제공하는 저작권자
패키저(Packager): 콘텐츠를 메타 데이터와 함께 배포 가능한 형태로 묶어 암호화하는 프로그램
콘텐츠 분배자(Contents Distributor): 암호화된 콘텐츠를 유통하는 곳이나 사람
콘텐츠 소비자(Customer): 콘텐츠를 구매해서 사용하는 주체
DRM 컨트롤러(DRM Controller): 배포된 콘텐츠의 이용 권한을 통제하는 프로그램
보안 컨테이너(Security Container): 콘텐츠 원본을 안전하게 유통하기 위한 전자적 보안 장치
디지털 저작권 관리의 기술 요소
- 암호화(Encryption): 콘텐츠 및 라이선스를 암호화하고 전자 서명을 할 수 있는 기술
- 키 관리(Key Management): 콘텐츠를 암호화한 키에 대한 저장 및 분배 기술
- 암호화 파일 생성(Packager): 콘텐츠를 암호화된 콘텐츠로 생성하기 위한 기술
- 식별 기술(Identification): 콘텐츠에 대한 식별 체계 표현 기술
- 저작권 표현(Right Expression): 라이언스의 내용 표현 기술
- 정책 관리(Policy Management): 라이선스 발급 및 사용에 대한 정책 표현 및 관리 기술
- 크랙 방지(Tamper Resistance): 크랙에 의한 콘텐츠 방지 기술
- 인증(Authentication): 라이선스 발급 및 사용의 기준이 되는 사용자 인증 기술
048. 소프트웨어 설치 매뉴얼 작성 (B)
사용자 기준으로 작성
설치 과정에 대한 모든 내용이 순서대로 빠짐없이 수록되어야 하며, 이해하기 쉽도록 캡처 화면으로 구성
설치 과정에서 표시될 수 있는 예외 상황에 관련 내용을 별도로 구분하여 설명
설치 매뉴얼에는 목차, 개요, 기본 사항 등이 기본적으로 포함되어야 함
049. 소프트웨어 사용자 매뉴얼 작성(C)
개별적으로 동작이 가능한 컴포넌트 단위로 작성
오류에 대한 패치나 기능에 대한 업그레이드를 위해 매뉴얼의 버전 관리
사용자가 설치와 사용에 필요한 절차, 환경 등의 제반 사항 모두가 포함되도록 작성
사용자가 기술 지원을 받기 위해 소프트웨어를 등록할 때 소프트웨어명, 소프트웨어 모델, 제품 번호, 구입 날짜 등을 기재할 수 있도록 관련 내용을 사용자 매뉴얼에 포함
구동 시 함께 실행해도 되는 응용 프로그램, 함께 실행하면 안 되는 응용 프로그램에 대해 설명
Profile은 소프트웨어의 구동 환경을 점검하는 파일로 위치를 변경하거나 이동하지 않도록 안내해야 함
(소프트웨어 사용자의 정보를 담고 있는 파일 X)
050. 소프트웨어버전 등록(A)
소프트웨어 패키징의 형상 관리(SCM; Software Configuration Management)는 소프트웨어의 개발 과정에서 소프트웨어의 변경 사항을 관리하기 위해 개발된 일련의 활동
- 변경의 원인을 알아내고 제어 하며 적절히 변경되고 있는지 확인해 담당자에게 통보함
- 소프트웨어 개발의 전 단계에 적용되는 활동이며 유지보수 단계에서도 수행됨
- 개발 전체 비용을 줄이고 방해 요인 최소화를 목적으로 함
형상 관리의 중요성
- 체계적인 추적과 통제
- 무절제한 변경의 방지
- 버그나 수정 사항 추적
- 진행 정도를 확인하는 기준
- 배포본의 효율적 관리
- 동시 개발 가능
형상 관리 기능
- 형상 식별: 형상 관리 대상에 이름과 관리 번호 부여하고, 계층(Tree) 구조로 구분하여 수정/추적 용이
- 버전 제어: 업그레이드, 유지 보수 과정에서 생성된 다른 버전의 형상 관리 및 특정 절차와 도구 결합
- 형상 통제(변경 관리): 변경 요구를 검토하여 현재의 기준선이 잘 반영될 수 있도록 조정
- 형상 감사: 기준선의 무결성을 평가하기 위해 확인, 검증, 검열 과정을 통해 공식적으로 승인
- 형상 기록(상태 보고): 형상의 식별, 통제, 감사 작업의 결과를 기록 및 관리하고 보고서 작성
소프트웨어의 버전 등록 관련 주요 기능
저장소(Repository): 최신버전의 파일들과 변경 내역에 대한 정보가 저장되어 있는 곳
가져오기(import): 버전 관리가 되고 있지 않은 아무것도 없는 저장소에 처음으로 파일 복사
체크아웃(Check-Out): 프로그램 수정을 위해 저장소에서 파일 받아옴
체크인(Check-In): 체크아웃 한 파일의 수정 완료 후 저장소에 파일을 새로운 버전으로 갱신
커밋(Commit): 체크인 수행 시 이전에 갱신 내용이 있는 경우 충돌을 알리고 diff 도구를 이용해 수정 후 갱신
동기화(Update): 저장소에 있는 최신 버전으로 자신의 작업 공간을 동기화
가져오기(import) —> 인출(Check-Out) —> 예치(commit) —> 동기화(update) —> 차이(diff)
051. 소프트웨어 버전 관리(B)
- 공유 폴더 방식: 버전 관리 자료가 로컬 컴퓨터에 저장되어 관리되는 방식
개발이 완료된 파일을 약속된 공유 폴더에 복사하고, 담당자는 공유 폴더의 파일을 자기 pc로 복사해
컴파일하여 이상 유무를 확인함
파일을 잘못 복사하거나 다른 위치로 복사하는 것에 대비해 파일의 변경 사항을 데이터베이스에 기록
- 클라이언트/서버 방식: 버전 관리 자료가 중앙 시스템(서버)에 저장되어 관리되는 방식
서버의 자료를 개발자별로 자신의 pc로 복사하여 작업한 후 변경된 내용을 서버에 반영
모든 버전 관리는 서버에서 수행
하나의 파일을 서로 다른 개발자가 작업할 경우 경고 메시지를 출력
서버에 문제가 생길 경우, 서버가 복구되기까지 협업 및 버전 관리 작업이 중단됨
ex) Subversion(서브버전, SVN)
CVS의 개선안으로 아파치 소프트웨어에서 발표함
서버의 자료를 클라이언트로 복사해 와 작업한 후 변경 내용을 서버에 반영(Commit)함
모든 개발 작업은 truck 디렉터리에서 수행되며, 추가 작업은 branches 디렉터리 안에 별도의
디렉터리를 만들어 작업 완료한 후 truck 디렉터리와 병합(merge)함
커밋할 때마다 리비전(Revision)이 1씩 증가
Subvision의 주요 명령어
Add: 새로운 파일이나 디렉터리를 버전 관리 대상으로 등록
Commit: 버전 관리 대상으로 등록된 클라이언트 소스 파일을 서버 소스 파일에 적용
Update: 서버의 최신 커밋 이력을 클라이언트 소스 파일에 적용
Checkout: 버전 관리 정보과 소스 파일을 서버에서 클라이언트로 받아옴
Lock/unlock: 서버의 소스 파일이나 디렉터리를 잠그거나 해제함
Import: 아무것도 없는 서버의 저장소에 맨 처음 소스 파일을 저장하는 명령으로 한 번만 사용함
Export: 버전 관리에 대한 정보를 제외한 순수한 소스 파일만 서버에서 받아옴
Info: 지정한 파일에 대한 위치나 마지막 수정 일자 등에 대한 정보 표시
Diff: 지정된 파일이나 경로에 대해 이전 리비전과의 차이를 표시
Merge: 다른 디렉터리에서 작업된 버전 관리 내역을 기본 개발 작업과 병합
- 분산 저장소 방식: 버전 관리 자료가 원격 저장소와 개발자 pc 로컬 저장소에 함께 저장되어 관리됨
원격 저장소의 자료를 자신의 로컬 저장소로 복사하여 작업한 후 변경된 내용을 로컬 저장소에서
우선 반영(버전 관리) 한 다음 이를 원격 저장소에 반영함
= 로컬 저장소에서 버전 관리 가능하므로 원격 저장소에 문제가 생겨도 로컬 저장소의 자료 활용 가능
ex) Git(깃)
리누스 토발즈가 개발한 이후 주니오 하마노에 의해 유지 보수되고 있음
지역 저장소는 개발자들이 실제 개발을 진행하는 장소로 버전 관리가 수행됨
원격 저장소는 여러 사람들이 협업을 위해 버전을 공동 관리 하는 곳
버전 관리가 지역 저장소에서 진행되므로 신속하며 원격 저장소나 네트워크 문제 있어도 작업 가능
브랜치를 이용하면 기본 버전 관리 틀에 영향을 주지 않으면서 다양한 형태의 기능 테스팅이 가능
파일의 변화를 스냅샷으로 저장하는데 이전 스냅샷의 포인터를 가지므로 버전의 흐름 파악 가능
Git의주요 명령어
Add: 작업 내역을 지역 저장소에 저장하기 위해 스테이징 영역에 추가
Commit: 작업 내역을 지역 저장소에 저장
Branch: 새로운 브랜치 생성, 최초로 커밋할 시 마스터 브랜치가 생성됨
Checkout: 지정한 브랜치로 이동
Merge: 지정한 브랜치 변경 내역을 현재 HEAD 포인터가 가리키는 브랜치에 반영하여 두 브랜치 병합
Init: 지역 저장소를 생성
Remote add: 원격 저장소에 연결
Push: 로컬 저장소의 변경 내역을 원격 저장소에 반영
Fetch: 원격 저장소의 변경 이력만을 지역 저장소로 가져와 반영
Clone: 원격 저장소의 전체 내용을 지역 저장소로 복제
Fork: 지정한 원격 저장소의 내용을 자신의 원격 저장소로 복제
052. 빌드 자동화 도구(B)
빌드란 소스 코드 파일들을 컴파일한 후 여러 개의 모듈을 묶어 실행 파일로 만드는 과정이며 이러한 빌드를 포함하여 테스트 및 배포를 자동화하는 도구를 빌드 자동화 도구라 함
애자일 환경에서는 하나의 작업이 마무리될 때마다 모듈 단위로 나눠서 개발된 코드들이 지속적으로 통합됨
= 지속적인 통합(Continuous Integration)
빌드 자동화 도구 대표적 종류
- Jenkins
JAVA 기반의 오픈 소스 형태, 가장 많이 사용되는 빌드 자동화 도구
서블릿 컨테이너에서 실행되는 서버 기반 도구
SVN, Git 등의 대부분의 형상 관리 도구와 연동 가능
친숙한 Wab GUI 제공으로 사용이 쉬움
여러 대의 컴퓨터를 이용한 분산 빌드나 테스트 가능
- Gradle
Groovy를 기반으로 한 오픈 소스 형태의 자동화 도구로 안드로이드 앱 개발 환경에서 사용됨
안드로이드뿐 아니라 플러그인 설정시 JAVA, C/C++, Python 등의 언어도 빌드 가능
Groovy를 사용해서 만든 DSL(Domain Specific Language)을 스크립트 언어로 사용
실행할 처리 명령들을 모아 태스크(Task)로 만든 후 태스크 단위로 실행함
이전에 사용했던 태스크를 재사용하거나 다른 시스템의 태스크를 공유할 수 있어 빌드 속도 향상
4장. 애플리케이션 테스트 관리
053. 애플리케이션 테스트(B)
애플리케이션에 잠재되어 있는 결함을 찾아내는 일련의 행위 또는 절차
개발된 소프트웨어가 고객의 요구사항을 만족시키는지 사용자 입장에서 확인(Validation)
개발된 소프트웨어가 명세서에 맞게 만들어졌는지 개발자 입장에서 검증(Verification)
애플리케이션 테스트의 필요성
- 프로그램 실행 전 오류 발견하여 예방 가능
- 요구사항이나 기대 수준을 만족하는지 반복적으로 테스트하므로 제품의 신뢰도 향상
- 애플리케이션 초기부터 테스트를 계획/시작하면 단순한 오류 발견 이상의 새로운 오류 유입도 예방
- 최소한의 시간과 노력으로 많은 결함을 찾을 수 있음
애플리케이션 테스트의 기본 원리
- 소프트웨어의 잠재적 결함을 줄일 수 있으나 결함이 없음을 증명할 수는 없음
즉, 완벽한 소프트웨어 테스팅은 불가능함
- 결함은 대부분 개발자의 특성이나 애플리케이션의 기능적 특징 때문에 특징 모듈에 집중됨
애플리케이션의 20%에 해당하는 코드에서 전체 80%의 결함이 발견되어 파레토 법칙 적용
- 동일한 테스트 케이스로 동일한 테스트 반복 시 더 이상 결함이 발견되지 않음
살충제 패러독스(Pesticide Paradox) 현상 방지를 위해 테스트 케이스를 지속 보완 및 개선해야 함
- 정황에 따라 테스트를 다르게 수행해야 함
- 결함을 모두 제거해도 사용자의 요구사항을 만족시키지 못하면 품질이 높다고 말할 수 없음
이를 오류-부재의 궤변(Absence of Errors Fallacy)이라고 함
- 테스트와 위험은 반비례: 테스트를 많이 할수록 미래에 발생할 위험을 줄일 수 있음
- 테스트는 작은 부분에서 시작하여 점점 확대하면서 진행
- 테스트는 개발자와 관계 없는 별도의 팀에서 수행해야 함
054. 애플리케이션 테스트의 분류(B)
- 프로그램 실행 여부에 따른 테스트
- 정적 테스트: 프로그램을 실행하지 않고 명세서나 소스 코드를 대상으로 분석하는 테스트
개발 초기에 결함을 발견할 수 있어 개발 비용을 낮추는 데 도움
종류: 워크스루, 인스펙션, 코드 검사 등
- 동적 테스트: 프로그램을 실행하여 오류를 찾는 테스트
소프트웨어 개발의 모든 단계에서 테스트 수행 가능
종류: 블랙박스 테스트, 화이트박스 테스트
- 테스트 기반(Test Bases)에 따른 테스트
- 명세 기반 테스트: 사용자의 요구사항에 대한 명세를 빠짐없이 테스트 케이스로 만들어 구현하고 있는지 확인하는 테스트
- 구조 기반 테스트: 소프트웨어 내부의 논리 흐름에 따라 테스트 케이스를 작성하고 확인하는 테스트
종류: 구문 기반, 결정 기준, 조건 기반 등
- 경험 기반 테스트: 유사 소프트웨어나 기술 등에 대한 테스터의 경험을 기반으로 수행하는 테스트
사용자 요구사항에 대한 명세가 불충분하거나 테스트 시간에 제약이 있는 경우에 효과적
종류: 에러 추정, 체크 리스트, 탐색적 테스팅
- 시각에 따른 테스트
- 검증(Verification) 테스트: 개발자의 시각에서 제품의 생산 과정을 테스트 / 명세서대로 완성됐는지
- 확인(Validation) 테스트: 사용자의 시각에서 생산된 제품의 결과 테스트 / 요구대로 완성됐는지, 정상적으로 동작하는지
- 목적에 따른 테스트
- 회복(Recovery) 테스트: 시스템에 여러 결함을 주어 실패하도록 한 후 올바르게 복구되는지
- 안전(Security) 테스트: 시스템 보호 도구가 불법 침입으로부터 시스템을 보호할 수 있는지
- 강도(Stress) 테스트: 과도한 정보량이나 빈도를 부과했을 때 과부화 시에도 정상 실행하는지
- 성능(Performance) 테스트: 실시간 성능이나 전체적 효율성을 진단하여 응답 시간, 처리량을 테스트
- 구조(Structure) 테스트: 소프트웨어 내부의 논리적인 경로, 소스 코드의 복잡도 등을 평가하는 테스트
- 회귀(Regression) 테스트: 변경 또는 수정된 코드에 새로운 결함이 없음을 확인
- 병행(Parallel) 테스트: 변경된 소프트웨어와 기존 소프트웨어에 동일한 데이터를 입력하여 결과 비교
055. 테스트 기법에 따른 애플리케이션 테스트(A)
- 화이트박스 테스트(White Box Test)
모듈의 원시 코드를 오픈시킨 상태에서 코드의 논리적인 모든 경로를 테스트하여 테스트 케이스 설계
원시 코드(모듈)의 모든 문장을 한 번 이상 실행함으로써 수행
모듈 안의 작동을 직접 관찰
설계된 절차에 초점을 둔 구조적 테스트, 프로시저 설계의 제어 구조를 사용하고 테스트 초기에 적용
화이트박스 테스트의 종류
- 기초 경로 검사(Base Path Testing): 절차적 설계의 논리적 복잡성 측정, 실행 경로의 기초 정의 지침
- 제어 구조 검사(Control Structure Testing)
- 조건 검사(Control Testing): 모듈 내에 있는 논리적 조건을 테스트하는 테스트 케이스 설계 기법
- 루프 검사(Loop Testing): 프로그램의 반복 구조에 초점을 맞추어 실시
- 데이터 흐름 검사(Data Flow Testing): 변수의 정의, 사용 위치에 초점을 맞추어 실시
화이트박스 테스트의 검증 기준
- 문장 검증 기준(Statement Coverage): 소스 코드의 모든 구문이 한 번 이상 수행되도록 설계
- 분기 검증 기준(Branch Coverage): 소스 코드의 모든 조건문이 한 번 이상 수행되도록 설계
- 조건 검증 기준(Condition Coverage): 소스 코드의 모든 조건문에 대해 조건이 True인 경우와 False인 경우가 한 번 이상 수행되도록 설계
- 분기/조건 기준(Branch/Condition Coverage): 소스 코드의 모든 조건문과 각 조건문에 포함된 개별 조건식의 결과가 True인 경우와 False인 경우가 한 번 이상 수행되도록 설계
2) 블랙박스 테스트(Black Box Test)
수행할 특정 기능을 알기 위해서 각 기능이 완전히 작동되는 것을 입증하는 테스트(= 기능 테스트)
사용자의 요구사항 명세를 보면서 테스트하는 것으로 주로 구현된 기능을 테스트 함
소프트웨어 인터페이스에서 실시되는 테스트로 테스트 과정의 후반부에 적용됨
블랙박스 테스트의 종류
- 동치 분할 검사(Equivalence Partitioning Testing, 동치 클래스 분해)
입력자료에 초점을 맞추어 테스트 케이스(동치 클래스)를 만들고 검사하는 방법(=동등 분할 기법)
입력 조건에 타당한 입력 자료와 타당하지 않은 입력 자료의 개수를 균등하게 하여
테스트 케이스를 정하고, 해당 입력 자료에 맞는 결과가 출력되는지 확인
- 경계값 분석(Boundary Value Analysis)
입력 자료에만 치중한 동치 분할 기법을 보완하기 위한 기법
중간값보다 경계값에서 오류 발생 확률이 높다는 점을 이용하여 경계값을 테스트 케이스로 선정
- 원인-효과 그래프 검사(Cause-Effect Graphing Testing)
입력 데이터 간의 관계와 출력에 영향을 미치는 상황을 체계적으로 분석한 다음
효용성이 높은 테스트 케이스를 선정하여 검사
- 오류 예측 검사(Error Guessing)
과거의 경험이나 확인자의 감각으로 테스트
보충적 검사 기법이며, 데이터 확인 검사라고도 함
- 비교 검사(Comparison Testing)
여러 버전의 프로그램에서 동일한 테스트 자료를 제공하여 동일 결과가 출력되는지 확인하는 기법
056. 개발 단계에 따른 애플리케이션 테스트(A)
소프트웨어 개발 단계: 요구사항(Requirements) —>분석(Specification) —>설계(Design) —> 구현(Code)
테스트 단계: 단위테스트(Unit Testing)—> 통합 테스트(Integration Testing)
—> 시스템 테스트(System Testing) —> 인수 테스트(Acceptance Testing)
두 가지 단계를 연결하여 표현한 것을 V 모델이라고 함
- 단위 테스트(Unit Test): 코딩 직후 소프트웨어 설계의 최소 단위인 모듈/컴포넌트에 초점을 둔 테스트
사용자의 요구사항을 기반으로 한 기능성 테스트를 최우선으로 수행
구조 기반 테스트: 프로그램 내부 구조 및 복잡도를 검증하는 화이트박스 테스트 시행 (주로 시행)
명세 기반 테스트: 목적 및 실행 코드 기반의 블랙박스 테스트 시행
- 통합 테스트(Integration Test): 단위 테스트 완료 모듈을 결합 후 하나의 시스템으로 완성시키는 과정 테스트
모듈 간 또는 통합된 컴포넌트 간의 상호 작용 오류를 검사
- 시스템 테스트(System Test): 개발된 소프트웨어가 해당 컴퓨터 시스템에서 완벽히 수행되는지 점검
기능적 요구사항 : 요구사항 명세서, 비즈니스 절차, 유스케이스 등 명세서 기반의 블랙박스 테스트
비기능적 요구사항: 성능, 회복, 보안, 내부 메뉴 구조 등구조적 요소에 대한 화이트박스 테스트 시행
- 인수 테스트(Acceptance Test): 사용자의 요구사항을 충족하는지에 중점을 두고 테스트
개발한 소프트웨어를 사용자가 직접 테스트함
인수 테스트에 문제가 없다면 사용자는 소프트웨어를 인수하고, 프로젝트는 종료됨
- 사용자 인수 테스트: 사용자가 시스템 사용의 적절성 여부 확인
- 운영상의 인수 테스트: 시스템 관리자가 시스템 인수 시 수행하는 테스트
- 계약 인수 테스트: 계약상의 인수/검수 조건을 준수하는지 여부 확인
- 규정 인수 테스트: 정부 지침, 법규, 규정 등에 맞게 개발되었는지 확인
- 알파 테스트: 개발자의 장소에서 사용자가 개발자 앞에서 행하는 테스트이며, 통제된 환경에서 행해지며 오류와 사용상의 문제점을 사용자와 개발자가 함께 확인하면서 기록
- 베타 테스트: 선정된 최종 사용자가 여러 명의 사용자 앞에서 행하는 테스트이며, 실업무를 사용자가 직접 테스트하고 개발자에 의해 제어되지 않은 상태로 진행됨! 오류와 사용상의 문제점을 기록하고 개발자에게 주기적으로 보고
057. 통합 테스트(A)
단위 테스트가 끝난 모듈을 통합하는 과정에서 발생하는 오류 및 결함을 찾는 테스트 기법
비점진적 통합 방식: 단계적 통합 절차 없이 모든 모듈이 결합되어 있는 프로그램 전체를 테스트
점진적 통합 방식: 모듈 단위로 단계적으로 통합하면서 테스트(하향/상향/혼합식이 있음)
점진적 통합 방식의 종류
- 하향식 통합 테스트(Top Down Integration Test): 상위 모듈 → 하위 모듈 방향으로 통합
깊이 우선 통합법과 넓이 우선 통합법이 있음
테스트 초기부터 사용자에게 시스템 구조를 보여 줄 수 있음
상위 모듈에서는 테스트 케이스를 사용하기 어려움
진행 방식
- 주요 제어 모듈은 작성된 프로그램 사용, 종속 모듈은 스텁(Stub)으로 대체
- 깊이/넓이 우선 등 통합 방식에 따라 하위 모듈인 스텁들이 1번에 1개씩 실제 모듈로 대체
- 모듈이 통합될 때마다 테스트 실시
- 새로운 오류 발생이 없음을 보증하기 위해 회귀 테스트 진행
*스텁(Stub): 제어 모듈이 호출하는 타 모듈의 기능을 단순히 수행하는 도구로,
일시적으로 필요한 조건만을 가지고 있는 시험용 모듈
- 상향식 통합 테스트(Bottom Up Integration Test): 하위 모듈 → 상위 모듈 방향으로 통합
주요 제어 모듈과 관련된 종속 모듈의 그룹인 클러스터(Cluster)가 필요함
진행 방식
- 하위 모듈을 클러스터로 결합
- 상위 모듈에서 데이터의 입출력을 확인하기 위해 더미 모듈인 드라이버(Driver) 작성
- 통합된 클러스터 단위로 테스트
- 완료 시 클러스터를 프로그램 상위로 이동시켜 결합하고, 드라이버는 실제 모듈로 대체
- 혼합식 통합 테스트: 하위 수준에서는 상향식, 상위 수준에서는 하향식을 사용하는 샌드위치식 통합 테스트
- 회귀 테스팅(Regression Testing)
이미 테스트된 프로그램의 테스팅을 반복하는 것
통합 테스트로 인해 변경된 모듈이나 컴포넌트에 새로운 오류가 있는지 확인하는 테스트
모든 테스트 케이스를 테스팅하는 게 좋으나 시간과 비용 절약을 위해 변경된 부분을
테스트할 수 있는 테스트 케이스를 선정하여 수행함
모든 기능을 수행할 수 있는 대표 테스트 케이스
변경에 의한 파급 효과 높은 테스트 케이스
실제 수정이 발생한 모듈/컴포넌트를 시행하는 테스트 케이스
058. 애플리케이션 테스트 프로세스(B)
테스트 계획 → 테스트 분석 및 디자인 → 테스트 케이스 및 시나리오 작성 → 테스트 수행 → 테스트 결과 평가 및 리포팅 → 결함 추적 및 관리
*오류는 될 수 있으면 빨리 발견하는 게 좋음(ex: 요구사항 분석 단계)
테스트 계획서: 테스트 목적, 범위, 일정, 절차, 대상 시스템 구조 등 테스트 수행을 계획한 문서
테스트 결과서: 테스트 결과를 비교/분석한 내용을 정리한 문서
059. 테스트 케이스/테스트 시나리오/테스트 오라클 (B)
- 테스트 케이스(Test Case): 사용자 요구사항을 얼마나 준수하는지 확인하기 위해 입력값, 실행 조건, 기대 결과 등으로 구성된 테스트 항목에 대한 명세서
명세 기반 테스트의 설계 산출물
이상적인 테스트 케이스를 설계하려면 시스템 설계 시 작성해야 함
- 테스트 시나리오(Test Scenario): 테스트 케이스를 적용하는 순서에 따라 여러 개의 테스트 케이스를 묶은 집합으로 테스트 케이스의 동작 순서를 기술한 문서
테스트 시나리오를 통해 순서를 미리 정함으로써 테스트 항목을 빠짐없이 수행 가능
유의 사항
- 시스템별/모듈별/항목별 등과 같이 여러 개의 시나리오로 분리하여 작성해야 함
- 사용자의 요구사항과 설계 문서 들을 토대로 작성해야 함
- 유스케이스(Use Case)간 업무 흐름이 정상적인지를 테스트할 수 있도록 작성
- 테스트 오라클(Test Oracle): 테스트 결과가 올바른지 판단하기 위해 사전에 정의된 참 값을 대입하여 비교하는 기법 및 활동
제한된 검증: 모든 테스트 케이스에 적용할 수 없음
수학적 기법: 테스트 오라클의 값을 수학적 기법을 이용해 구할 수 있음
자동화 기능: 대상 프로그램의 실행, 결과 비교, 커버리지 측정 등을 자동화 할 수 있음
테스트 오라클의 종류
- 참(True) 오라클: 모든 테스트 케이스의 입력값에 대해 기대하는 결과를 제공하는 오라클로 발생된 모든 오류 검출 가능 / 미션 크리티컬한 업무에 사용
- 샘플링(Sampling) 오라클: 특정한 테스트 케이스의 입력값들에 대해서만 기대 결과 제공
- 추정(Heuristic) 오라클: 샘플링 오라클 개선한 오라클로, 특정 테스트 케이스의 입력값에 대해 기대하는 결과를 제공하고 나머지 입력값에 대해서는 추정으로 처리
- 일관성 검사(Consistent) 오라클: 애플리케이션의 변경이 있을 때 테스트 케이스의 수행 전후의 결과값이 동일한지 확인하는 오라클
060. 테스트 자동화 도구(B)
사람이 반복적으로 수행하던 테스트 절차를 스크립트 형태로 구현하는 자동화 도구를 적용함으로써 쉽고 효율적으로 테스트 수행 가능하도록 한 것
재사용 및 측정이 불가능한 테스트 프로그램은 제외해야 함
반드시 프로젝트 초기에 테스트 엔지니어의 투입 시기를 고려해야 함
*스크립트 형태: 소스 코드를 컴파일하지 않고도 내장된 번역기에 의해 바로 실행 가능한 언어
테스트 자동화 도구의 장단점
- 재입력, 재구성 같은 반복 작업을 자동화함으로써 인력 및 시간을 줄임
- 향상된 테스트 품질 보장
- 일관성 있는 검증 가능하며 객관적 평가 기준 제공
- 결과를 그래프 등 다양한 표시 형태로 제공
- UI 없는 서비스도 정밀 테스트 가능
- 사용 방법에 대한 교육 및 학습이 필요함
- 프로세스 단계별로 적용하기 위한 시간/비용/노력이 필요
- 비공개 상용 도구의 경우 고가의 추가 비용 필요
061. 결함 관리(C)
결함: 소프트웨어가 개발자가 설계한 것과 다르게 동작하거나 결과가 발생되는 것
일반적으로 결함의 심각도(high, medium, low)가 높으면 우선 순위도 높지만 애플리케이션 특성에 따라 우선 순위가 결정될 수도 있기 때문에 심각도가 높다고 우선 순위가 반드시 높은 건 X
결함 상태 측정 지표
결함 분포: 모듈 또는 컴포넌트의 특정 속성에 해당하는 결함 수 측정
결함 추세: 테스트 진행 시간에 따른 결함 수의 추이 분석
결함 에이징: 특정 결함 상태로 지속되는 시간 측정
062. 애플리케이션 성능 분석(C)
애플리케이션 성능 측정 지표
- 처리량(Throughput): 일정 시간 내에 애플리케이션이 처리하는 일의 양
- 응답 시간(Response Time): 애플리케이션에 요청을 전달한 시간부터 응답이 도착할 때까지 걸린 시간
- 경과 시간(Turn Around Time): 애플리케이션에 작업을 의뢰한 시간부터 처리가 완료될 때까지 걸린 시간
- 자원 사용률(Resource Usage): 애플리케이션이 의뢰한 작업을 처리하는 동안의 CPU 사용량, 메모리 사용량, 네트워크 사용량 등 자원 사용률
애플리케이션 성능 저하 원인 분석
- DB에 필요 이상의 많은 데이터 요청한 경우
- DB의 락이 해제되기를 바라면서 애플리케이션이 대기하거나 타임아웃된 경우
- 커넥션 풀(Connection Pool)의 크기를 너무 작거나 크게 설정한 경우
- 미들웨어를 사용한 후 종료하지 않아 연결 누수(Connection Leak)가 발생한 경우
- 대량의 파일을 업로드하거나 다운로드하여 처리 시간이 길어진 경우
063. 복잡도(A)
시스템 구성 요소 또는 소프트웨어의 복잡한 정도를 나타내는 말
- 시간 복잡도: 알고리즘을 수행하기 위해 프로세스가 수행하는 연산 횟수를 수치화한 것을 의미하며 시간이 아닌 명령어의 실행 횟수를 표기하는 점근 표기법 사용
시간 복잡도가 낮을수록 알고리즘의 실행시간이 짧고, 높을수록 실행시간 길어짐
알고리즘 실행 시간에 따라 빅오 표기법(최악), 세타 표기법(평균), 오메가 표기법(최상)
빅오 표기법(Big-O Notation): 알고리즘 실행시간 최악일 때의 표기법, 성능 예측 용이
O(1): 입력값(n)에 관계 없이 일정하게 문제 해결에 하나의 단계만을 거침
ex) 스탭의 삽입(push), 삭제(pop)
O(log2n): 문제 해결에 필요한 단계가 입력값(n) 또는 조건에 의해 감소
ex) 이진 트리(Binary Tree), 이진 검색(Binary Search)
O(n): 문제 해결에 필요한 단계가 입력값(n)과 1:1 관계를 가짐
ex) for문
O(nlong2n): 문제 해결에 필요한 단계가 n(log2n)번만큼 수행
ex) 힙 정렬(Heap Sort), 2-way 합병 정렬(Merge Sort)
O(n²): 문제 해결에 필요한 단계가 입력값(n)의 제곱만큼 수행
ex) 삽입 정렬(Insertion Sort), 쉘 정렬(Shall Sort), 선택 정렬(Selection Sort),
버블 정렬(Bubble Sort), 퀵 정렬(Quick Sort)
O(2ⁿ): 문제 해결에 필요한 단계가 2의 입력값(n) 제곱만큼 수행
ex) 피보나치 수열(Fibonacci Sequence)
- 순환 복잡도
논리적인 복잡도를 측정하기 위한 소프트웨어의 척도로 맥케이브 순환도(McCabe’s Cyclematic)라고도 하며, 제어 흐름도 이론에 기초를 둠
프로그램의 독립적인 경로의 수를 정의하고 모든 경로가 한 번 이상 수행되었음을 보장하기 위해 행해지는 테스트 횟수의 상한선을 제공
순환 복잡도 V(G) = E - N + 2 : E는 화살표 수, N은 노드의 수
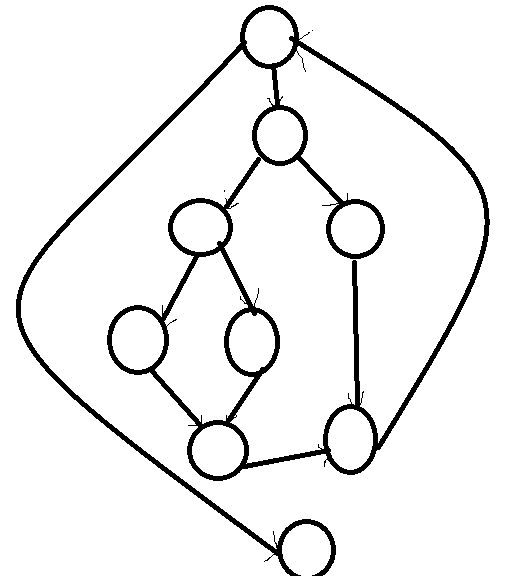
화살표 수: 11개, 노드 수: 9개이므로 순환복잡도 = 11 - 9 + 2 = 4
064. 애플리케이션 성능 개선(A)
소스 코드 최적화
나쁜 코드(Bad Code)를 배제하고, 클린 코드(Clean Code)로 작성하는 것
클린 코드(Clean Code): 누구나 쉽게 이해하고 수정 및 추가할 수 있는 단순명료한 코드
나쁜 코드(Bad Code): 프로그램 로직이 복잡하고 이해하기 어려운 코드
- 스파게티 코드: 코드의 로직이 서로 복잡하게 얽혀 있는 코드
- 외계인 코드: 아주 오래되거나 참고 문서 또는 개발자가 없어 유지보수 작업이 어려운 코드
클린 코드 작성 원칙
- 가독성: 누구든지 코드를 쉽게 읽을 수 있도록 작성, 이해하기 쉬운 언어와 들여쓰기 기능
- 단순성: 코드를 간단하게 작성, 한 번에 한 가지를 처리하도록, 최소 단위로 분리
- 의존성 배제: 코드가 다른 모듈에 미치는 영향을 최소화, 변경 시 다른 부분 영향 없도록
- 중복성 최소화: 중복을 최소화, 중복 코드 삭제 및 공통된 코드 사용
- 추상화: 상위에서는 애플리케이션의 특성을, 하위에서는 상세 내용을 구현함
소스 코드 최적화 유형
- 클래스 분할 배치: 하나의 클래스는 하나의 역할만 수행하도록 응집도 높이고, 크기 작게
- 느슨한 결합(Loosely Coupled): 인터페이스 클래스를 이용해 추상화된 자료 구조를 구현함으로써 의존성 최소화
- 코딩 형식 준수: 줄바꿈과 개념적 유사성 높은 종속 함수 사용, 지역 변수는 맨 처음 선언
- 좋은 이름 사용: 기본적 이름 명명 규칙 정의
- 적절한 주석문 사용
소스 코드 품질 분석 도구
정적 분석 도구: 작성한 코드 실행하지 않고 코딩 표준이나 스타일, 결함 등을 확인하는 분석 도구
애플리케이션 개발 초기의 결함을 찾는 데 사용, 개발 완료 시점에서는 코드의 품질 검증으로 사용
동적 도구로 발견 어려운 결함을 찾아내고 코딩의 복잡도, 모델 의존성, 불일치성 등을 분석 가능
종류: pmd, cppcheck, SonarQube, checkstyle, ccm, cobertura 등
동적 분석 도구: 작성한 코드 실행하여 코드에 존재하는 메모리 누수, 스레드 결합 등을 분석
종류: Avalanche, Valgrind, valMeter 등
5장. 인터페이스 구현
065. 모듈 간 공통 기능 및 데이터 인터페이스 확인(C)
공통 기능: 모듈의 기능 중에서 공통적으로 제공되는 기능
데이터 인터페이스: 모듈 간 교환되는 데이터가 저장될 파라미터를 의미함
인터페이스 설계서: 시스템 사이의 데이터 교환 및 처리를 위해 교환 데이터 및 관련 업무, 송수신 시스템 등에 대한 내용을 정의한 문서
인터페이스 설계서별 모듈 기능 확인
- 시스템 인터페이스 목록에서 송신 및 전달은 외부 / 수신은 내부 모듈
- 시스템 인터페이스 설계서에서 데이터 송신 시스템은 외부 / 데이터 수신은 내부 모듈
- 상세 기능 인터페이스 명세서에서 오퍼레이션과 사전 조건은 외부 / 사후 조건은 내부
- 정적/동적 모형을 통한 인터페이스 설계에서 인터페이스 영역은 내부 / 나머지는 외부
066. 모듈 연계를 위한 인터페이스 기능 식별(A)
모듈 연계: 내부 모듈과 외부 모듈 또는 내부 모듈 간 데이터의 교환을 위해 관계를 설정하는 것
모듈 연계 방법
EAI(Enterprise Application Integration)
기업 내 각종 애플리케이션 및 플랫폼 간의 정보 전달, 연계, 통합 등 상호 연동이 가능하게 해 주는 솔루션이며, 비즈니스 간 통합 및 연계성을 증대시켜 효율성 및 각 시스템 간의 확정성을 높임
- Point-to-Point: 가장 기본적인 애플리케이션 통합 방식으로 애플리케이션을 1:1로 연결하며, 변경 및 재사용이 어려움
- Hub & Spoke: 단일 접점인 허브 시스템을 통해 데이터를 전송하는 중앙 집중형 방식,
확장 및 유지 보수가 용이하며 허브 장애 발생 시 시스템 전체에 영향을 미침
- Message Bus(ESB 방식): 애플리케이션 사이에 미들웨어를 두어 처리하는 방식이며,
확장성이 뛰어나며 대용량 처리가 가능함
- Hybrid: Hub&Spoke와 Message Bus의 혼합 방식, 필요한 경우 한 가지 방식으로 가능
그룹 내에서는 Hub&Spoke 방식, 그룹 간에는 Message Bus 방식을 사용함
데이터 병목 현상을 최소화할 수 있음
ESB(Enterprise Service Bus)
애플리케이션 간 연계, 데이터 변환, 웹 서비스 지원 등 표준 기반의 인터페이스를 제공하는 솔루션
통합 측면에서 EAI와 유사하지만 애플리케이션보다는 서비스 중심의 통합을 지향함
특정 서비스에 국한되지 않고 범용적으로 사용하기 위해 애플리케이션과의 결합도를 약하게 함
관리 및 보안 유지가 쉽고 높은 수준의 품질 지원이 가능함
067. 모듈 간 인터페이스 데이터 표준 확인(D)
인터페이스 데이터 표준: 모듈 간 인터페이스에 사용되는 데이터의 형식을 표준화하는 것
인터페이스 데이터 표준은 기존의 데이터 중에서 공통 영역을 추출하거나 어느 한 쪽의 데이터를 변환하여 정의하며, 데이터 표준은 인터페이스 기능 구현을 정의하는 데 사용됨
068. 인터페이스 기능 구현 정의(C)
컴포넌트 명세서 확인 → 인터페이스 명세서 확인 → 일관된 인터페이스 기능 구현 정의 → 정의된 인터페이스 기능 구현을 정형화
모듈 세부 설계서는 모듈의 구성 요소와 세부적인 동작 등을 정의한 설계서
종류에는 컴포넌트 명세서, 인터페이스 명세서가 있음
069. 인터페이스 구현(B)
송수신 시스템 간의 데이터 교환 및 처리를 실현해 주는 작업
- 데이터 통신을 이용한 인터페이스 구현
애플리케이션 영역에서 인터페이스 형식에 맞춘 데이터 포맷을 인터페이스 대상으로
전송하고 이를 수신 측에서 파싱(Parsing; 완전한 문장으로 사용될 수 있는지 확인)
하여 해석하는 방식
JSON(JavaScript Object Notation): 속성-값-쌍으로 이루어진 데이터 객체를 전달하기
위해 사람이 읽을 수 있는 텍스트를 사용하는 개방형 표준 포맷
비동기 처리에 사용되는 AJAX에서 XML을 대체하여 사용
XML(eXtensible Markup Language): 특수한 목적을 갖는 마크업 언어를 만드는 데
사용되는 다목적 마크업 언어로, HTML 문법이 각 웹 브라우저에서 상호 호환적이지 못한
문제와 SGML의 복잡함을 해결하기 위해 개발
AJAX(Asynchronous JavaScript and XML)
자바 스크립트 등을 이용하여 클라이언트와 서버 간의 XML 데이터를 교환 및
제어함으로써 이용자가 웹 페이지와 자유롭게 상호작용할 수 있도록 한 비동기 통신 기술
- 인터페이스 엔티티를 이용한 인터페이스 구현
인터페이스가 필요한 시스템 사이에 별도의 인터페이스 엔티티를 두어 상호 연계하는 방식
070. 인터페이스 예외 처리(B)
구현된 인터페이스가 동작하는 과정에서 기능상 예외 상황이 발생했을 때 이를 처리하는 절차
071. 인터페이스 보안(A)
시스템 모듈 간 통신 및 정보 교환을 위한 통로로 사용되므로 충분한 보안 기능을 갖추지 않으면 시스템 모듈 전체에 악영향을 주는 보안 취약점이 될 수 있음
인터페이스 보안 기능 적용
- 네트워크 영역: 인터페이스 송수신 간 스니핑(Sniffing; 네트워크 중간에서 남의 패킷 정보를 도청하는 해킹 유형의 수동적 공격) 등을 이용한 데이터 탈취 및 변조 위협을 방지하기 위해 네트워크 트래픽에 대한 암호화 설정
종류: IPSec, SSL, S-HTTP 등
- 애플리케이션 영역: 소프트웨어 개발 보안 가이드를 참조하여 애플리케이션 코드상의 보안 취약점을 보완하는 방향으로 애플리케이션 보안 기능 적용
- 데이터베이스 영역: DB, 스키마, 엔티티의 접근 권한과 프로시저, 트리거 등 DB 동작 객체의 보안 취약점에 보안 기능을 적용하며 개인 정보 등을 암호화, 익명화 하여 데이터 자체의 보안 방안도 고려함
소프트웨어 개발 보안: 애플리케이션 소스 코드에 존재할 수 있는 보안 취약점의 발견, 제거, 보안을 고려한 기능 설계 및 구현 등 소프트웨어 개발 과정에서 지켜야 할 일련의 보안 활동으로 시큐어 코딩(Secure Coding)이라고도 함
데이터 무결성 검사 도구
시스템 파일의 변경 유무를 확인하고 파일이 변경되었을 경우 관리자에게 알려 주는 도구로, 인터페이스 보안 취약점을 분석하는 데 사용됨
크래커나 허가받지 않은 내부 사용자들이 시스템에 침입하면 백도어를 만들고 시스템 파일을 변경하여 자신의 흔적을 감추는데, 무결성 검사 도구를 이용해 이를 감지할 수 있음
해시(Hash) 함수를 사용하여 현재 파일 및 디렉토리 상태를 DB에 저장한 후 감시하다가 상태가 달라지면 관리자에게 변경 사실을 알림
데이터 무결성 검사 도구: Tripwire, AIDE, Samhain, Claymore, Slipwire, Fcheck 등
072. 연계 테스트(C)
연계 테스트 케이스 작성 → 연계 테스트 환경 구축 → 연계 테스트 수행 → 연계 테스트 수행 결과 검증
073. 인터페이스 구현 검증(A)
인터페이스가 정상적으로 문제 없이 작동하는지 확인하는 것
- 인터페이스 구현 검증 도구: 인터페이스 단위 기능과 시나리오 기반의 통합 테스트 필요
xUit: JAVA(Junit), C++(Cppunit), Net(Nunit) 등 다양한 언어를 지원하는 단위 테스트 프레임워크
STAF: 서비스 호출 및 컴포넌트 재사용 등 다양한 환경을 지원하는 테스트프레임워크로
크로스 플랫폼, 분산 소프트웨어 환경을 조성할 수 있도록 지원함
분산 소프트웨어의 경우, 각 환경에 설치된 데몬이 프로그램 테스트에 대한 응답을 대신함
FitNesse: 웹 기반 테스트케이스 설계, 실행, 결과 확인 등을 지원하는 테스트 프레임워크
NTAF: FitNesse의 장점인 협업 기능과 STAF의 장점인 재상용 및 확장성을 통합한 NHN(Naver)의 테스트 자동화 프레임워크
Selenium: 다양한 브라우저 및 개발 언어를 지원하는 웹 애플리케이션 테스트 프레임워크
watir: Ruby를 사용하는 애플리케이션 테스트 프레임워크
- 인터페이스 구현 감시 도구: APM을 사용하여 감시(Monitoring) 가능
리소스 방식과 엔드투엔드 방식(스카우터[Scouter], 제니퍼[Jennifer]) 등이 있음
074. 인터페이스 오류 확인 및 처리 보고서 작성(D)
인터페이스는 독립적으로 떨어져 있는 시스템 간 연계를 위한 기능이므로 인터페이스에서 발생하는 오류는 대부분 중요한 오류임
인터페이스 오류 즉시 확인: 사용자에게 오류 메시지 표시, 관리자/사용자에게 오류 SMS 발송, 오류 이메일 발송
주기적인 인터페이스 오류 발생 확인: 오류 로그 확인, 오류 테이블 확인, 감시 도구(APM) 사용