문제 1. 아래 보기 중 반정규화의 이유로 가장 부적절 한 것은?
| 1) 데이터를 조회할 때 디스크 입출력량이 많아서 성능이 저하될 때 반정규화를 수행한다. 2) 데이터 무결성을 보장하지 못할 때 반정규화를 수행한다. 3) 경로가 너무 멀어 조인으로 인한 성능 저하가 예상될 때 반정규화를 수행한다. 4) 칼럼을 계산하여 읽을 때 성능이 저하 될 것이 예상되는 경우 반정규화를 수행한다. |
1. 정답 : 2
해설 : 반정규화를 하면 데이터 무결성을 해친다.
| 구분 | 설명 |
| 반정규화의 대상 분석 | - 디스크 I/O량이 많아 성능저하 - 경로가 너무 멀어 조인으로 성능저하 - 컬럼을 계산하여 읽을 때 성능 저하 |
| 반정규화 개념 | - 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터 모델을 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배하는 행위 |
| - 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성을 증가시키지만 데이터의 일관성 및 정합성이 저하될 수 있다. - 과도한 반정규화는 오히려 성능을 저하시킨다. - 반정규화를 위해서는 사전에 데이터의 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지를 결정해야 한다. - 방정규화 방법에는 테이블 통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등이 있다. |
|
| 테이블 통합 | 두 개의 테이블에서 발생하는 프로세스가 동일하게 자주 처리되는 경우, 두 개의 테이블을 이용하여 항상 조회를 수행하는 경우 테이블 통합을 고려한다. |
문제 2. 아래의 ERD 처럼 분산데이터베이스 설계가 되어 있을 때 가장 부적절한 것은?

| 1) 하나의 결과에는 여러 개의 계획이 있을 수 있다. 2) 한 개의 계획에는 내용이 없을 수도 있다. 3) 데이터 조회 성능을 위해서 공통된 속성은 하나의 테이블로 묶을 수 있다. 4) 데이터 무결성을 보장하지 못할 때 분산 데이터베이스 설계가 좋다. |
2. 정답 : 4
해설 : 분산데이터베이스는 데이터의 무결성을 완전히 보장하는 것이 불가능하다.
문제 3. ANSI-SPARC에서 정의한 3단계 구조(Three Level Architecture)에서 아래 내용이 설명하는 스키마 구조로 가장 적절한 것은?
| - 모든 사용자관점을 통합한 조직 전체 관점의 통합적 표현이다. - 모든 응용시스템들이나 사용자 들이 필요로 하는 데이터를 통합한 조직 전체의 DB를 기술한 것으로 DB에 저장되는 데이터와 그들 간의 관계를 표현하는 스키마이다. |
| 1) 외부 스키마 (External Schema) 2) 개념 스키마 (Conceptual Schema) 3) 내부 스키마 (Internal Schema) 4) 논리 스키마 (Logical Schema) |
3. 정답 : 2
해설 :
외부 스키마 : 사용자 관점
개념 스키마 : 통합 관점
내부 스키마 : 물리적 관점
문제 4. 다음 보기 중 ERD에서 Relationship(관계)에 표시되지 않는 것은 무엇인가?
| 1) 관계 명 (Relationship Membership) 2) 관계 차수 (Relationship Degree/Cardinality) 3) 관계 선택 사양 (Relationship Optionality) 4) 관계 분류 (Relationship Classification) |
4. 정답 : 4
해설 : 관계를 표기법은 관계명, 관계차수, 관계선택사양 세 가지로 이루어져 있다.
관
계명(Membership)
관계명은 엔터티간 관계에 맺어진 형태 뜻한다.
관계가 시작되는 쪽을 "관계시작점(The Beginning)"이라 칭하며 받는쪽을 "관계끝점(The End)"라고 칭한다.
또한 관점에 따라 능동적(Active)이거나 수동적(Passive)으로 명명된다.
관계차수(Degree/Cardinality)
관계차수란 두 엔터티간 관계에서 수행되는 경우의 수를 뜻한다.
관계선택사양(Optionality)
관계에서 항상 참여하는지 아니면 참여할 수도 있는지를 나타내는 방법따라 필수참여 관계(Mandatory), 선택참여 관계(Optional)로 나뉜다.
고객과 주문 엔터티 관계를 살펴보자. 3명의 손님의 가게에 들어왔다. 하지만 2명의 손님만 주문을 시킬 경우도 있다.
주문은 꼭 손님에 의해서 수행이 되지만, 손님은 주문을 시킬수도 있고 안 시킬수도 있다.
이처럼 주문은 손님에의해 수행이 될수도 있고 안 될수도 있어서 선택참여 관계이고 주문된 항목은 꼭 손님에 의해서 수행이 되어져야 하므로 필수참여 관계이다.
선택참여관계일 경우 ERD에서 관계를 나타내는 선에서 선택참여하는 엔터티쪽에 원을 표시해야한다.
문제 5. 다음 보기 중 분산 데이터베이스에 대한 특징으로 부적절한 것은?
| 1) 지역 자치성, 점증적 시스템 용량이 확장된다. 2) 빠른 응답속도와 통신비용을 절감할 수 있다. 3) 데이터 처리 비용이 증대한다. 4) 데이터 무결성을 보장하고 데이터 보안성이 높아진다. |
5. 정답 : 4
해설 :
분산 데이터베이스
장 점 -지역 자치성, 점증적 시스템 용량 확장
-신뢰성과 가용성
-효용성과 융통성
-빠른 응답속도와 통신비용 절감
-데이터의 가용성과 신뢰성 증가
-시스템 규모의 적절한 조절
-각 지역 사용자의 요구 수용 증대
단 점 -소프트웨어 개발 비용
-오류의 잠재성 증대
-처리비용의 증대
-설계, 관리의 복잡성과 비용
-불규칙한 응답 소고
-통제의 어려움
-데이터의 무결성에 대한 위협
문제 6. 아래의 두 가지 모델에 대한 설명으로 가장 적절한 것은?


| 1) 수학 과목 신청에 관한 내용을 조회할 때 '가' 모델이 '나' 모델보다 좋다. 2) 하나의 SQL로 하나도 수강하지 않은 과목을 찾을 수 없다. 3) 정규화 측면에서는 '나' 모델이 '가' 모델보다 우수하다. 4) 두 개의 모델의 장점은 동일하다. |
6. 정답 : 3
해설 : '가' 모델의 수강과목 엔터티를 보면 1정규형을 위반한 것이 보인다.
문제 7. 아래와 같은 테이블이 있을 때 그 설명으로 부적절 한 것은?

| 1) 4개의 테이블을 조인하기 위한 최소 조건은 3개이다. 2) 식별자 관계로만 연결될 경우 조인의 복잡성이 증가하므로 비식별자 관계를 고려해야 한다. 3) Student, Module을 조인할 때 Student와 Grades를 비식별자 관계로 설계하면 조인이 더욱 편리해진다. 4) Student의 student_ID는 내부 식별자 이고 Grades의 student_ID는 외부 식별자이다. |
해설 : 테이블 조인 조건 계산( n - 1 )
Student, Grade를 비식별자 관계로 설계하면 Grade, Module은 식별자 관계이므로 Student, Module을 설계 할 때 오히려 조인의 복잡성이 커질 수 있다.
식별자 분류 식별자 설명
대표성여부
주식별자 - 엔터티 내에서 각 행을 구분할 수 있는 구분자이며, 타 엔터티와 참조관계를 연결할 수 있는 식별자 (ex. 사원번호, 고객번호)
보조식별자 - 엔터티 내에서 각 행을 구분할 수 있는 구분자이나 대표성을 가지지 못해 참조관계 연결을 못함(ex. 주민등록번호)
스스로생성여부 내부식별자 - 엔터티 내부에서 스스로 만들어지는 식별자(ex. 고객번호)
외부식별자 - 타 엔터티와의 관계를 통해 타 엔터티로부터 받아오는 식별자(ex. 주문엔터티의 고객번호)
속성의 수 단일식별자 - 하나의 속성으로 구성된 식별자(ex. 고객엔터티의 고객번호 )
복합식별자 - 둘 이상의 속성으로 구성된 식별자(ex. 주문상세엔터티의 주문번호+상세순번)
대체여부 본질식별자 - 업무에 의해 만들어지는 식별자(ex. 고객번호)
인조식별자 - 업무적으로 만들어지지는 않지만 원조식별자가 복잡한 구성을 가지고 있기 때문에 인위적으로 만든 식별자(ex. 주문엔터티의 주문번호(고객번호+주문번호+순번))
문제 8. 다음 보기 중 테이블 설계 시 인덱스와 관련된 설명으로 부적절한 것은?
| 1) 주로 B-Tree 인덱스로 되어 있다. 2) 외래키가 설계되어 있는데 인덱스가 없는 상태에서 입력/삭제/수정의 부하가 생긴다. 3) 테이블에 만들 수 있는 인덱스의 수는 제한이 없으나, 너무 많이 만들면 오히려 성능 부하가 발생한다. 4) 조회는 일반적으로 인덱스가 있는 것이 유리하다. |
8. 정답 : 2
해설 : 외래키가 설계되어 있지만 인덱스가 없는 상태라면 입력/삭제/수정의 부하가 덜 생긴다.
문제 9. 아래의 ERD에 대한 설명으로 가장 부적절한 것은?
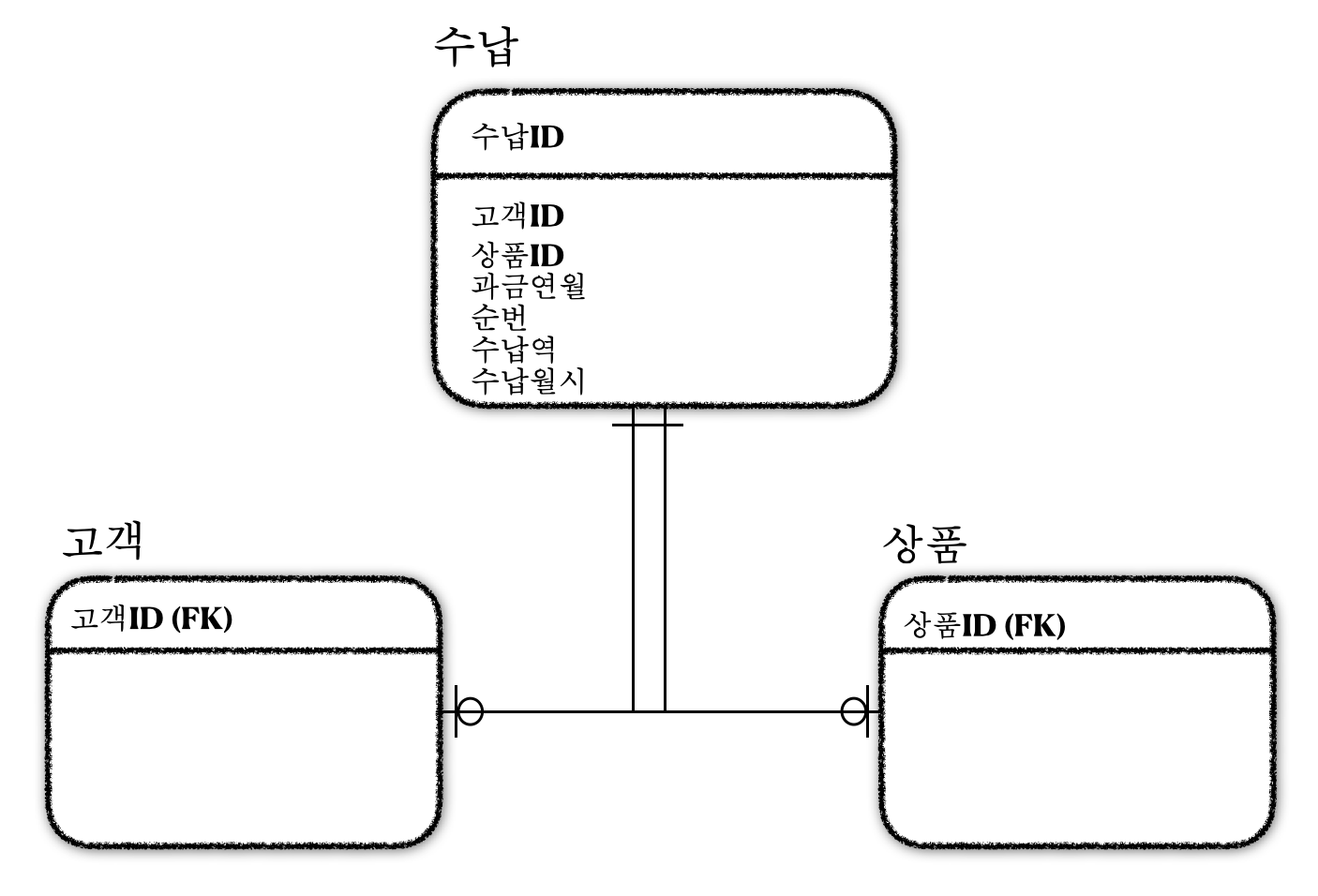
| 1) 자주 쓰는 컬럼과 그렇지 않은 컬럼으로 나눠서 성능을 향상 시킬 수 있다. 2) Row Chaining이 발생하여 속도가 느려질 수 있다. 3) 한 테이블에 많은 수의 컬럼들이 존재하게 되면 데이터가 디스크의 여러 블록 에 존재하므로 디스크에서 데이터를 읽는 I/O 량이 많아지게 되어성능이 저하 될 수 잇다. 4) 데이터 로우가 과도하게 밀집되지 않도록 스키마 구조와 동일하게 파티션을 분할한다. |
9. 정답 : 4
해설 : ROW의 정보를 검색하기 위해 하나 이상의 데이터 블록을 SCAN해야하기 때문에 성능이 감소될 수 있다.
구분
Row Chaining
Row Migration
정의
하나의 Row를 하나의 블록에 저장할 수 없어서 여러 블록에 걸쳐서 저장하는 현상
Update로 인하여 늘어나는 공간을 저장할 공간이 없어서 다른 블록으로 Row를 옮기는 현상
특성
Initial Row Piece(행 조작)와 Row Pointer로 블록 내에 저장됨
기존 블록에는 Migration되는 데이터의 row header와 블록 주소값을 갖게 되고, 새로운 블록에는 Migration되는 데이터가 저장됨
문제점
Row의 정보를 검색하기 위해 하나 이상의 데이터 블록을 Scan해야 하기 때문에 성능이 감소됨
Migration된 Row를 읽기 전에 기존 블록에서 헤더를 통해 Migration된 Row를 읽기 때문에 성능이 감소됨
해결책
블록의 크기를 크게 만든다.
-PCTFREE를 크게 설정
-객체를 Export하고 삭제한 후 import
-객체를 Migration하고
Truncate
문제 10. 테이블 반정규화 기법 중 테이블 병합이 아닌 것은?
| 1) 1:1 관계 테이블 병합 2) 1:M 관계 테이블 병합 3) 슈퍼/서브 타입 테이블 병합 4) 통계 테이블 추가 |
10. 정답 : 4
해설 : 통계 테이블 추가는 테이블 추가에 해당한다.
기법분류
기법
내용
테이블
병합
1:1 관계 테이블 병합
1:1 관계를 통합하여 성능향상
1:M 관계 테이블 병합
1:M 관계를 통합하여 성능향상
슈퍼/서브타입 테이블 병합
슈퍼/서브 관계를 통합하여 성능 향상
테이블
분할
수직분할
컬럼 단위의 테이블을 디스크 I/O를 분산처리하기 위해 테이블을 1:1로 분리하여 성능향상(트랜잭션의 처리되는 유형파악이 선행되어야 함)
수평분할
행(레코드)단위로 집중 발생되는 트랜잭션을 분석하여 디스크 I/O 및 데이터 접근의 효율성을 높여 성능을 향상하기 위해 행 단위로 테이블을 쪼갬
테이블
추가
중복테이블 추가
다른 업무이거나 서버가 다른 경우 동일한 테이블 구조를 중복하여 원격 조인을 제거하고 성능을 향상
통계테이블 추가
SUM, AVG 등을 미리 수행하여 계산해 둠으로써 조회 시 성능을 향상
이력테이블 추가
이력테이블 중에서 마스터 테이블에 존재하는 레코드를 중복하여 이력 테이블에 존재하는 방법
문제 11. 아래의 ANSI JOIN SQL에서 가장 올바르지 않은 것은?
| 1) SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME FROM EMP INNER JOIN DEPT ON EMP.DEPTNO = DEPT.DEPTNO; 2) SELECT EMP.DEPTNO, EMPNO, ENAME, DNAME FROM EMP NATURAL JOIN DEPT; 3) SELECT*FROM DEPT JOIN DEPT_TEMP USING(DEPTNO); 4) SELECT E.EMPNO, E.ENAME, D.DEPTNO, D.DNAME FROM EMP E INNER JOIN DEPT D ON (E.DEPTNO = D.DEPTNO); |
11. 정답 : 2
해설 : NATURAL JOIN에서 EMP.DEPTNO와 같이 OWNER 명을 사용하면 에러 발생
문제 12. 아래의 SQL 구문 중 결과가 다른 것은?
| 1) SELECT C1, C2 FROM SQLD_31_26_01 NATURAL JOIN SQLD_31_26_02; 2) SELECT NO, A.C1, B.C2 FROM SQLD_31_26_01 A JOIN SQLD_31_26_02 B USING (NO); 3) SELECT A.NO, A.C1, B.C2 FROM SQLD_31_26_01 A JOIN SQLD_31_26_02 B ON (A.NO = B.NO); 4) SELECT A.NO, A.C1, B.C2 FROM SQLD_31_26_01 A CROSS JOIN SQLD_31_26_02 B; |
12. 정답 : 4
해설 : 1,2,3번은 2개의 테이블에서 동일한 이름을 가지는 칼럼에 대해서 조인을 수행하는 방식이고 4번은 두 테이블의 모든 데이터에 대해서 조인을 수행하는 CROSS JOIN 방식임.
문제 13. UNION에 대한 설명 중 바른 것은?
| 1) 데이터의 중복 행을 제거한다. 2) 데이터의 중복 행을 포함한다. 3) 정렬 작업을 수행하지 않는다. 4) 두 테이블에 모두 포함된 행을 검색한다. |
13. 정답 : 1
해설 : UNION은 중복된 행을 제거하고 정렬한다. UNION ALL은 합집합
문제 14. 다음 보기 중 SQL의 결과가 다른 것은?
[SQLD_14]
--------------------------------
NUM CODE COL1 COL2
1 A 100 350
2 A 130 300
3 B 150 400
4 A 200 300
5 B 250 200
6 A 300 150| 1) SELECT*FROM SQLD_14 WHERE 1=1 AND CODE IN('A','B') AND COL1 BETWEEN 200 AND 400; 2) SELECT*FROM SQLD_14 WHERE 1=1 AND (CODE='A' AND 200 BETWEEN COL1 AND COL2) OR (CODE='B' AND 200 BETWEEN COL1 AND COL2); 3) SELECT*FROM SQLD_14 WHERE 1=1 AND 200 BETWEEN COL1 AND COL2; 4) SELECT*FROM SQLD_14 WHERE 1=1 AND COL1 <= 200 AND COL2 >= 200; |
해설 : 1번은 200<= A <=400, 200<= B <=400의 의미이고 나머지는 모두 COL1<=200 && COL2>=200를 의미함
문제 15. 다음 보기 중 트랜잭션의 특징이 아닌 것은?
| 1) 원자성 2) 일관성 3) 연관성 4) 고립성 |
15. 정답 : 3
해설 : ACID
Atomicity(원자성)
Consistency(일관성)
Isolation(고립성)
Durability(영속성)
문제 16. 다음 중 아직 COMMIT 되지 않은 데이터에 대한 설명으로 잘못된 것은?
| 1) ROLLBACK 명령어로 바로 직전에 COMMIT한 지점까지 데이터를 복구할 수 있다. 2) 나 자신이 볼 수 있다. 3) 다른 사용자가 볼 수 없다. 4) 다른 사용자가 COMMIT되지 않은 변경된 데이터를 고칠 수 있다. |
16. 정답 : 4
해설 : COMMIT이 완료되지 않은 데이터를 다른 사용자가 고칠 수 없다.(고립성)
문제 17. 다음 보기 중 COL1 NULL이 없는 데이터를 찾는 SQL로 올바른 것은?
| 1) SELECT COL1 FROM WHERE T1 WHERE COL1 <> '' 2) SELECT COL1 FROM WHERE T1 WHERE COL1 != '' 3) SELECT COL1 FROM WHERE T1 WHERE COL1 IS NOT NULL 4) SELECT COL1 FROM WHERE T1 WHERE COL1 NOT IN (NULL) |
17. 정답 : 3
해설 : NULL은 오로지 IS NULL, IS NOT NULL로만 조회가 가능
문제 18. 다음 주어진 데이터에서 아래의 결과값과 같이 "_" 들어가 있는 ?
[SQLD_18]
ID NAME
------------
1 ___A
2 B
3 ___C
4 D
5 E
6 ___F
[결과값]
ID NAME
------------
1 _A
3 __C
6 ___F| 1) SELECT*FROM SQLD_18 WHERE NAME LIKE '%%'; 2) SELECT*FROM SQLD_18 WHERE NAME LIKE '%#_%'; 3) SELECT*FROM SQLD_18 WHERE NAME LIKE '%@_%' ESCAPE '@'; 4) SELECT*FROM SQLD_18 WHERE NAME LIKE '%_%' ESCAPE '_'; |
18. 정답 : 3
해설 : LIKE 연산으로 %나 _가 들어간 문자를 검색하기 위해서는 ESCAPE 명령어를 사용할 수 있다. 사용 방법은 _나 % 앞에 ESCAPE로 특수 문자를 지정하면 검색할 수 있다.
문제 19. 다음 주어진 테이블에서 수행한 SQL문의 결과값으로 잘못된 것은?
19. 정답 : 2
해설 : ROWNUM = 1은 사용 가능 하지만 ROWNUM = 2인 경우는 데이터가 추출되지 않는다.
(ROWNUM은 WHERE절을 만족하는 레코드에 붙이는 순번이므로 해석해 보면,
ROWNUM = 2는, 처음 한 건 추출해서 ROWNUM이 2인지 비교하는 것이다.
하지만 처음 레코드는 ROWNUM이 1이며, 조건에 맞지 않다.
문제 20. 다음 주어진 SQL문의 결과값이 다른 것은?
[SQLD_20]
COL1 COL2 COL3
-----------------------
A 300 50
B 300 150
C NULL 300
D 300 100
SELECT NVL(COL2, COL3) AS 금액1,
COALESCE(COL2, COL3) AS 금액2,
NULLIF(COL2, COL3) AS 금액3,
CASE WHEN COL2 IS NOT NULL THEN
COL2 ELSE COL3 END AS 금액4
FROM SQLD_20;| 1) 금액 1 2) 금액 2 3) 금액 3 4) 금액 4 |
20. 정답 : 3
해설 :
금액1 : 300 -> NVL(=ISNULL) A가 NULL이면 B로 가고, 아니면 A를 출력
금액2 : 300 -> COALESCE NULL이 아닌 최초값 출력
금액3 : NULL -> NULLIF A와 B의 값이 같으면 NULL, 아니면 A를 출력
금액4 : 300 -> CASE WHEN A IS NOT NULL THEN A ELSE B END : A가 NOT NULL이면 A 출력, 아니면 B 출력
문제 21. 다음 중 차집합을 구하는 집합 연산자는 무엇인가?
| 1) UNION 2) UNION ALL 3) EXCEPT 4) INTERSECT |
21. 정답 : 3
해설 : SQL server (EXCEPT) / Oracle (MINUS)
문제 22. 아래의 WINDOW FUNCTION을 사용한 SQL 중 가장 올바르지 않은 것은?
| 1) SUM(SAL) OVER() 2) SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) SAL1 3) SUM(SAL) OVER(PARTITION BY JOB ORDER BY JOB RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) SAL2 4) SUM(SAL) OVER(PARTITION BY JOB ORDER BY EMPNO RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED PRECEDING) SAL3 |
22. 정답 : 4
해설 :
UNBOUNDED PRECEDING은 end point에서 사용될 수 없다.
RANGE BETWEEN start_point AND end_point
-start point는 end_point와 같거나 작은 값이 들어간다.
-Default값은 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW가 된다.
-UNBOUNDED PRECEDING : start_point만 들어갈 수 있으며 파티션의 first row가 된다.
-UNBOUNDED FOLLOWING : end_point만 들어갈 수 있으며 파티션의 last_row가 된다.
-CURRENT ROW : start_point, end_point 둘 다 가능하다. 윈도우는 CURRENT ROW에서 start하거나 end한다.
문제 23. 인덱스에 대한 특징으로 잘못된 것은?
| 1) Insert, Update, Delete 등과 같은 DML 작업은 테이블과 인덱스를 함께 변경해야 하기 때문에 오히려 속도가 느려질 수 있다. 2) 인덱스 사용의 목적은 검색 성능의 최적화이다. 3) 인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬을 수행한다. 4) 인덱스는 Equal 조건만 사용할 수 있다. |
23. 정답 : 4
해설 :인덱스 중 B-트리 인덱스는 Equal 조건뿐 아니라 BETWEEN, > 과 같은 연산자로 검색하는 범위 검색에도 사용될 수 있다.
인덱스의 특징
- 인덱스는 원하는 데이터를 쉽게 찾을 수 있도록 돕는 책의 색인과 유사한 개념이다.
- 인덱스는 테이블을 기반으로 선택적으로 생성할 수 있는 구조이다.
- 인덱스의 기본적인 목적은 검색 성능의 최적화이다.
- 검색 조건을 만족하는 데이터를 인덱스를 통해 효과적으로 찾을 수 있도록 돕는다.
- DML작업은 테이블과 인덱스를 함께 변경하므로 느려지는 단점이 존재한다.
- 인덱스 데이터는 인덱스를 구성하는 칼럼의 값으로 정렬을 수행한다.
문제 24. 다음()에 해당되는 Subquery의 이름으로 올바른 것은?
SELECT (ㄱ)
FROM (ㄴ)
WHERE = (ㄷ);| 1) 스칼라 서브쿼리, 인라인뷰, 서브쿼리 2) 인라인뷰, 인라인뷰, 스칼라 서브쿼리 3) 메인쿼리, 인라인뷰, 서브쿼리 4) 서브쿼리, 인라인뷰, 메인서브쿼리 |
24. 정답 : 1
해설 :
서브쿼리 설명
SELECT
스칼라 서브쿼리 스칼라 서브쿼리는 한 행, 한 컬럼만을 반환하는 서브쿼리를 말합니다.
FROM
인라인 *뷰 서브쿼리가 FROM 절에 사용되면 동적으로 생성된 테이블인 것처럼 사용할 수 있습니다.
인라인 뷰는 SQL 문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 데이터베이스에 해당 정보가 저장되지 않습니다.
WHERE / HAVING
서브쿼리 그룹함수와 함께 사용될 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해 사용합니다.
구분 설명
*뷰 개념
VIEW 테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다.
질의에서 뷰가 사용되면 뷰 정의를 참조해서 DBMS 내부적으로 질의를 재작성하여 질의를 수행
뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블이라고도 한다.
독립성 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다.
편리성 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다.
보안성 숨기고 싶은 정보가 존재하는 경우, 뷰를 생성할 때 해당 컬럼을 빼고 생성하여 정보를 숨길 수 있다.
문제 25. 다음 중 PL/SQL에 대한 설명으로 가장 적절하지 않은 것은?
| 1) 변수와 상수 등을 사용하여 일반 SQL 문장을 실행할 때 WHERE절의 조건 등 으로 대입할 수 있다. 2) Procedure, User Defined Function, Trigger 객체를 PL/SQL로 작성 할 수 있다. 3) Procedure 내부에 작성된 절차적 코드는 PL/SQL 엔진이 처리하고 일반적인 SQL 문장은 SQL 실행기가 처리한다. 4) PL/SQL 문의 기본 구조로 DECLARE, BEGIN ~ END, EXCEPTION은 필수적으로 써야 한다. |
25. 정답 : 4
해설 : 예외처리는 필수가 아니다.
문제 26. 다음 중 데이터 무결성을 보장하기 위한 방법으로 가장 부적절한 것은?
| 1) 애플리케이션 2) Trigger 3) Lock 4) 제약조건 |
26. 정답 : 3
해설 : Lock/Unlock은 병행성 제어(동시성) 기법이다.
무결성 : 데이터 임의 갱신으로부터 보호해야 하는 것.
제약조건을 넣어서 무결성을 보장하거나, Triger 로직 안에 검사 기능을 넣을 수도 있고, 개발자의 코딩에서 로직을 넣을 수도 있다.
문제 27. 아래의 SQL문을 수행하였을 때의 결과가 Result와 같을 때 Result에 대한 설명으로 적절하지 않은것은?
<SQL>
SELECT CONNECT BY ROOT LAST_NAME AS BOSS
MANAGER_ID, EMPLOYEE_ID, LAST_NAME,
LEVEL,
CONNECT BY_ISLEAF,
SYS_CONNECT_BY_PATH(LAST_NAME.'-')"PATH",
FROM SQLD_27
WHERE 1=1 START WITH MANAGER_ID IS NULL
CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID[RESULT]
BOSS MANAGER_ID EMPLOYEE_ID LAST_NAME LEVEL CONNECT_BY_ISLEAFPATH
----------------------------------------------------------------------
[ ] 100 A 0 -A
A 100 101 B 0 -A-B
A 101 108 C 0 -A-B-C
A 101 205 L 0 -A-B-L
A 108 109 D 1 -A-B-C-D
A 108 110 E 1 -A-B-C-E
A 108 111 F 1 -A-B-C-F
A 108 112 G 1 -A-B-C-G
A 108 113 H 1 -A-B-C-H
A 101 200 I 1 -A-B-I
A 101 203 J 1 -A-B-J
A 101 204 K 1 -A-B-K
A 205 206 M 1 -A-B-L-M| 1) [ ]는 A이다. |
| 2) LEAF 면 1을 LEAF가 아니면 0을 반환한다. |
| 3) 자식에서 부모로 가는 역방향이다. |
| 4) LEVEL은 계층의 깊이를 의미하며 KING은 최상위 계층이다. |
27. 정답 : 3
해설 : MANAGER_ID IS NULL 로 시작했기 때문에 부모에서 자식으로 조회하는 정방향이다.
문제 28. 아래의 SQL문에 대한 설명으로 올바른 것은?
SELECT*FROM SQLD_28
WHERE EMP NAME LIKE 'A%';| 1) 테이블의 EMP NAME이 A 또는 a로 시작하는 모든 ROW 2) 테이블의 EMP NAME이 A로 시작하는 모든 ROW 3) 테이블의 EMP NAME이 A로 끝나는 모든 ROW 4) 테이블의 EMP NAME이 A또는 a로 끝나는 모든 ROW |
28. 정답 : 2
해설 : _ (한글자), A%(A로 시작하는), %A(A로 끝나는)
문제 29. 다음 주어진 테이블에서 SQL문의 결과값으로 알맞은 것은?
[SQLD_29]
JOB_TITLE EMP_NAME SALARY
---------------------------------
CLERK JACSON 2000
SALESMAN KING 3000
SALESMAN BOAN 4000
CLERK LUCAS 5000
SALESMAN CADEN 6000
CLERK GRAYSON 7000
DEVELOPER LOGAN 8000
CLERK JIM 9000
[RESULT]
SELECT COUNT(*)
FROM SQLD_29
WHERE JOB_TITLE = 'CLERK'
OR (EMP_NAME LIKE 'K%' AND SALARY >= 3000)| 1) 4건 2) 5건 3) 6건 4) 8건 |
29. 정답: 2
해설 : CLERK행 + K로 시작하는 연봉 3000이상 반환
문제 30. 다음 중 문자열이 입력될 때 빈 공간으로 채우는 형태의 데이터 타입은?
|
1) VARCHAR2
2) CHAR 3) DATE 4) NUMBER |
30. 정답 : 2
해설 : CHAR(10)으로 칼럼을 생성하고 8개의 문자를 입력하면 나머지 2개는 공백으로 입력된다. VARCHAR2는 가변길이 문자열 타입으로 입력한 크기만큼 할당된다.
문제 31. 다음 중 결과값이 다른 것은?
| 1) SELECT SUBSTR(TO_CHAR('20190504'),5,2) FROM DUAL; 2) SELECT EXTRACT(MONTH FROM DATE '2020-05-01') FROM DUAL; 3) SELECT CONCAT('0', '5') FROM DUAL; 4) SELECT TRIM('05') FROM DUAL; |
31. 정답 : 2
해설 : 2번만 5를 반환하고 나머지는 '05'를 반환
SUBSTR 문자열 슬라이싱 -> '20190504'의 5번째 '0'에서 2번째까지 -> '05'
EXTRACT (YEAR/MONTH/DAY FROM SYSDATE) 연,월,일을 뽑아서 출력 -> 5(문자열 아님)
CONCAT 문자열 결합 -> '05'
TRIM 공백 제거 -> '05'
문제 32. 다음 중 결과값이 다른 것은?
|
1) SELECT UPPER('ebac') FROM DUAL;
2) SELECT RTRIM(' EBAC') FROM DUAL; 3) SELECT SUBSTR('ABCEBACED',4,4) FROM DUAL; 4) SELECT CONCAT('EB','AC') FROM DUAL; |
32. 정답 : 2
해설 :
UPPER 대문자로 변환 -> 'EBAC'
RTRIM 오른쪽 공백 제거 -> ' EBAC'
SUBSTR 문자열 슬라이싱 -> 'ABCEBACED'의 4번째 'EBACED'에서 4번째까지 -> 'EBAC'
CONCAT 문자열 결합 -> 'EBAC'
문제 33. 다음 보기 중 아래 SQL문의 결과값으로 올바른 것은?
<SQL>
SELECT SUBSTR('123456788',-4,2)
FROM DUAL;| 1) 45 2) 65 3) 43 4) 67 |
33. 정답 : 4
해설 : 뒤에서 4번째 자리값인 6부터 2개 반환 -> 67
문제 34. 주어진 SQL문의 빈칸에 올 수 있는 함수로 옳지 않는 것은?
[SQLD_34]
DEPT NAME SALARY
------------------------------
MARKETING A 30
SALES B 40
MARKETING C 40
SALES D 50
MANUFACTURE E 50
MARKETING F 50
MANUFACTURE G 60
SALES H 60
MANUFACTURE I 70
SELECT*FROM SQLD_34
WHERE SALARY ( );| 1) <= (SELECT MAX(SALARY) FROM SQLD_34 GROUP BY DEPT) 2) >= ANY(30,40,50,60,70) 3) <= ALL(30,40,50,60,70) 4) IN (SELECT SALARY FROM SQLD_34 WHERE DEPT = 'MARKETING') |
34. 정답 : 1
해설 :
단일행 서브쿼리
-서브쿼리의 실행 결과가 항상 1건 이하인 서브쿼리
-항상 비교연산자와 함께 사용된다.
-비교연산자 뒤에는 단일행이 와야 하는데 뒤에 GROUP BY DEPT는 다중행 함수로 멀티행을 반환하여 에러가 발생함.
다중행 서브쿼리
-서브쿼리의 실행 결과가 여러 건인 서브쿼리
-메인 쿼리의 조건 절에 여러 칼럼을 동시에 비교할 수 있다.
-서브쿼리와 메인쿼리의 칼럼 수와 칼럼 순서가 동일해야 한다.
문제 35. 다음 중 아래의 요구사항을 반영한 SQL문의 결과가 다른 것은?
[요구사항]
팀이 A이거나 B이면서 무게가 65보다 큰 플레이어를 검색해라.(1)
SELECT*FROM PLAYER
WHERE TEAM IN('A','B') AND WEIGHT > 65;
(2)
SELECT*FROM PLAYER
WHERE TEAM = 'A' OR TEAM = 'B' AND
WEIGHT > 65;
(3)
SELECT*FROM PLAYER
WHERE (TEAM = 'A' AND WEIGHT > 65) OR
(TEAM = 'B' AND WEIGHT > 65);
(4)
SELECT *FROM PLAYER
WHERE (TEAM = 'A' OR TEAM = 'B') AND
WEIGHT > 65;35. 정답 : 2
해설 : 연산자 우선순위에 따라 몸무게 65인 모든 사람을 뽑고 A OR B인 팀도 뽑음
문제 36. 다음 중 데이터베이스 테이블의 제약조건(CONSTRAINT)에 대한 설명으로 가장 부적절한 것은?
| 1) Check 제약조건은 데이터베이스에서 데이터의 무결성을 유지하기 위하여 테이블의 특정 칼럼에 설정하는 제약이다. 2) 기본키(Primary Key)는 반드시 테이블 당 하나의 제약만을 정의할 수 있다. 3) 고유키(Unique Key)로 지정된 모든 칼럼들은 Null 값을 가질 수 없다. 4) 외래키(Foreign Key)는 테이블 간의 관계를 정의하기 위해 기본키(Primary Key)를 다른 테이블의 외래키가 참조하도록 생성한다. |
36. 정답 : 3
해설 : 고유키로 지정된 모든 칼럼은 중복된 값을 허용하진 않지만 NULL값은 가질 수 있다.
문제 37. 주어진 테이블에서 SQL문을 수행하였을 때 T1, T2, T3의 결과 건수로 알맞은 것은?
[SQLD_37]
COL1
--------
1
2
3
INSERT FIRST
WHEN C1 >= 2 THEN INTO T1
WHEN C1 >= 3 THEN INTO T2
ELSE INTO T3
SELECT*FROM SQLD_37;| 1) 0, 1, 2 2) 2, 0, 1 3) 1, 2, 0 4) 0, 2, 1 |
37. 정답 : 2
해설 : 다중행 입력 쿼리문으로 Case문과 동일하게 수행되며 WHEN을 만족하면 종료한다.
그래서 T1행에는 2, 3 T2행에는 NULL, T3행에는 1이 입력된다.
문제 38. 문자열 중 m위치에서 n개의 문자 길이에 해당하는 문자를 리턴하는 함수를 고르시오.
| 1) SUBSTR(STR, M, N) / SUBSTRING(STR, M, N) 2) TRIM(STR, M, N) 3) CONCAT(STR, M, N) 4) STRING_SPLIT(STR, M, N) |
38. 정답 : 1
해설 : STRING_SPLIT : 조회된 skills 컬럼의 쉼표(',') 구분자를 잘라서 해당 개수만큼 행으로 변환한다.
FROM절에서 해당 함수를 사용할 수 있다.
문제 39. 아래와 같은 데이터를 가진 테이블이 있을 때 아래의 SQL 결과로 알맞은 것은?
[SQLD_39]
COL1 COL2
--------------
1 A
1 A
1 A
1 B
SELECT COUNT(COL1), COUNT(COL2)
FROM (
SELECT DISTINCT COL1, COL2
FROM SQLD_39
);| 1) 1, 2 2) 2, 1 3) 2, 2 4) 3, 3 |
39. 정답 : 3
해설 : FROM절에서 DISTINCT 명령어로 중복된 COL1, COL2값은 제외되어 COL1, COL2가 (1, A), (1,B)인 2개의 행만 반환되고 각각 COUNT값 2를 반환한다.
문제 40. 다음 주어진 테이블에 대한 아래의 SQL문의 결과 건수로 알맞은 것은?
[SQLD_40]
COL1 COL2
---------------
A 100
B 200
C 300
C 400
SELECT COUNT(*)
FROM SQLD_40
GROUP BY ROLLUP(COL1), COL1;|
1) 3
2) 4 3) 6 4) 8 |
40. 정답 : 3
해설 : a 기준 집계 두번 한 결과
"롤업을 하면 총계가 나온다"
롤업은 괄호 안의 항목들을 오른쪽부터 하나씩 지워나가면서 집계한다.
예를 들면 ROLLUP(a, b) 는
1. (a, b) 합계
2. (a) 합계
3. () 합계
이렇게 3가지 형태의 집계 결과가 나오게 된다.
ROLLUP(a), a 를 보면
1. (a), a
2. (), a
이렇게 두가지 형태의 집계 결과가 나오게 된다.
a 가 두번 나오나 한번 나오나 다 같은 a 기준 집계 결론은 a 기준 집계 두번 한 결과
문제 41. 다음 주어진 SQL문과 동일한 결과값을 반환하는 SQL문으로 올바른 것은?
SELECT*FROM T1
WHERE COL1 BETWEEN A AND B;(1)
SELECT*FROM T1
WHERE COL1 >= :A AND COL1 <= :B
(2)
SELECT*FROM T1
WHERE COL1 <= :A AND COL1 >= :B
(3)
SELECT*FROM T1
WHERE COL1 >= :A OR COL1 <= :B
(4)
SELECT*FROM T1
WHERE COL1 <= :A OR COL1 <= :B41. 정답 : 1
해설 :
연산자 연산자의 의미
BETWEEN a AND b a와 b의 값 사이에 있으면 된다.
(a와 b의 값이 포함됨)
:a<=COL<=B
IN(list) 리스트에 있는 값 중에서 어느 하나라도 일치하면 된다.
LIKE '비교문자열' 비교문자열과 형태가 일치하면 된다.
IS NULL NULL 값인 경우
문제 42. 아래와 같은 테이블에 데이터가 있다. 각 보기에서의 SQL실행 결과가 잘못된 것은?
[SQLD_42_1] [SQLD_42_2]
JOB_TITLE NAME JOB_TITLE NAME
------------------ --------------------
MANAGER A MANAGER A
CLERK B
SALESMAN C SALESMAN C
DEVELOPER D(1) (2)
SELECT A.JOB_TITLE, A.NAME SELECT A.JOB_TITLE, A.NAME
FROM SQLD_42_1 A, SQLD_42_2 B FROM SQLD_42_1 A LEFT OUTER JOIN SQLD_42_2 B
WHERE A.JOB_TITLE = B.JOB_TITLE; ON A.JOB_TITLE = B.JOB_TITLE;
<RESULT> <RESULT>
JOB_TITLE NAME JOB_TITLE NAME
------------------ ------------------
MANAGER A DEVELOPER D
SALESMAN C
(3) (4)
SELECT A.JOB_TITLE, A.NAME SELEC A.JOB_TITLE, A.NAME
FROM SQLD_42_1 A FROM SQLD_42_1 A INNER JOIN SQLD_42_2 B
RIGHT OUTER JOIN SQLD_42_2 B ON A.JOB_TITLE = B.JOB_TITLE;
ON A.JOB_TITLE = B.JOB_TITLE;
<RESULT> <RESULT>
JOB_TITLE NAME JOB_TITLE NAME
------------------ ------------------
MANAGER A CLERK
SALESMAN C SALESMAN C42. 정답 : 2
해설 : LEFT OUTER JOIN 이므로 SQLD_42_1 컬럼의 데이터가 다 출력되어야 한다.
문제 43. 주어진 데이터에 대해서 SQL의 결과가 아래와 같을 때 SQL문의 빈칸을 완성하시오.
[SQLD_43]
이름 부서 직책 급여
----------------------------
조조 경영지원부 부장 300
유비 경영지원부 과장 290
제갈량 인사부 대리 250
사마의 인사부 대리 250
관우 영업부 사원 230
장비 영업부 사원 220
- - - - - - - - - - - - - - - - -
SELECT( ) OVER (ORDER BY 급여 DESC)
AS 순위,
이름, 부서, 직책, 급여
FROM SQLD_43;
[Result1]
순위 이름 부서 직책 급여
-----------------------------------
1 조조 경영지원부 부장 300
2 유비 경영지원부 과장 290
3 제갈량 인사부 대리 250
3 사마의 인사부 대리 250
5 관우 영업부 사원 230
6 장비 영업부 사원 220
- - - - - - - - - - - - - - - - -
SELECT( ) OVER (ORDER BY 급여 DESC)
AS 순위,
이름, 부서, 직책, 급여
FROM SQLD_43;
[Result2]
순위 이름 부서 직책 급여
-----------------------------------
1 조조 경영지원부 부장 300
2 유비 경영지원부 과장 290
3 제갈량 인사부 대리 250
4 사마의 인사부 대리 250
5 관우 영업부 사원 230
6 장비 영업부 사원 22043. 정답 : RANK(), ROW_NUMBER()
해설 : 그룹 내 순위함수
RANK() : 중복값은 중복등수, 등수 건너뜀(1위, 1위, 3위, 4위)
DENSE_RANK() : 중복값은 중복등수, 등수 안 건너뜀(1위, 1위, 2위, 2위)
ROW_NUMBER() : 중복값이 있어도 고유 등수 부여(1위, 2위, 3위, 4위)
문제 44. 아래의 SQL을 수행한 결과를 작성하시오.
<SQL>
SELECT ROUND(3.45. 1) AS COL1 FROM DUAL;44. 정답 : 3.5
해설 : ROUND 함수의 첫 번째 인자값인 3.45를 소수점 첫째 자리까지 반올림
문제 45. 다음 보기에서 설명하는 조인은 무엇인가?
- Equal Join(동등 조인)에서만 가능하다.
- 대용량 처리에 유리하다.
- 각 테이블에 INDEX가 반드시 필요한 것은 아니다.
- 데이터 건수가 적은 테이블을 선행 테이블로 두는 것이 유리하다.45. 정답 : HASH JOIN
HASH JOIN 이란?
-조인 컬럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있다.
-해시 함수를 이용하여 조인을 수행하기 때문에 '='로 수행하는 조인으로 동등 조건에만 사용가능
-해시 함수가 적용될 때 동일한 값을 항상 같은 값으로 해싱됨이 보장된다.
-HASH JOIN 작업을 수행하기 위해 해시 테이블을 메모리에 생성해야 한다.
-메모리에 적재할 수 있는 영역의 크기보다 커지면 임시 영역(디스크)에 해시 테이블을 저장한다.
-HASH JOIN을 할 때는 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋다.
-선행 테이블을 Build input이라 하며, 후행 테이블을 Prove input이라 한다.
문제 46. 아래 두 개의 SQL이 같은 결과를 출력하도록 SQL을 완성하시오.
[SQLD_46]
상품명 상품코드 단가
-------------------------
가 A 1000
나 D 2000
다 G 3000
가 B 4000
나 E 5000
가 C 6000
다 H 7000
나 F 8000
- - - - - - - - - - - - - - -
SELECT 상품명, SUM(단가)
FROM SQLD_46
WHERE 상품명 = '가'
GROUP BY ROLLUP(상품명);
SELECT 상품명, SUM(단가)
FROM SQLD_46
WHERE 상품명 = '가'
GROUP BY GROUPING SETS( );46. 정답 : 상품명, ()
문제 47. 아래의 설명에서 괄호에 알맞은 것은?
테이블에 데이터를 입력할 때 INSERT를 사용하며, 입력한 정보 중에 잘못 입력되거나
변경이 발생하여 정보를 수정해야 하는 경우 ( )를 사용한다.
또한 테이블의 정보가 필요 없게 되었을 경우 데이터 삭제를 위하여 DELETE를 사용한다.47. 정답 : UPDATE
해설 : UPDATE ~ SET ( 수정 )
INSERT INTO (입력)
DELETE (삭제)
문제 48. 데이터의 입력/삭제/수정 등의 DML 수행 후 원상 복구를 위한 명령어를 쓰시오.
48. 정답 : ROLLBACK
해설 : 복구명령어
문제 49. 아래의 SQL에 대한 Column Header를 적으시오(DBMS : Oracle)
<SQL>
SELECT employee_id, DEPARTMENT_ID, SALARY AS " salary"
FROM SQLD_49
WHERE EMPLOYEE_ID < 110;49. 정답 : EMPLOYEE_ID, DEPARTMENT_ID, salary
해설 :* 별칭이 없는 칼럼은 대문자로 바뀌고, 별칭이 있는 칼럼은 그대로 사용
(SQL Server의 경우는 별칭이 없는 칼럼도 그대로 사용)
문제 50. 아래 데이터를 가진 테이블에 대한 SQL결과를 적으시오.
[SQLD_50]
COL1 COL2
--------------
1
2
3 1
4 1
5 2
6 2
7 3
8 4
9 5
10 6
- - - - - - -
SELECT COUNt(*)
FROM SQLD_50
WHERE COL1 <> 4
START WITH COL1 = 1
CONNECT BY PRIOR COL1 = COL2;50. 정답 : 4
해설 : 위 테이블에서 계층형 쿼리 결과로 총 5건(1,3,7,4,8)이 조회되면 여기서 WHERE 조건절인 COL1<>인 4번째 행이 제외되어 총 4건이 나온다.