![[HTTP] 섹션4. HTTP 메소드](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbd4bl3%2FbtssB1jXWnI%2Frid8j8pKTfobkksAURVBvk%2Fimg.png)
🔥 모든 개발자를 위한 HTTP 웹 기본 지식
섹션4. HTTP 메소드
📍 HTTP API를 만들어 보자
👉🏻 요구사항: 회원 정보 관리 API를 만들어라!
1) 회원 목록 조회
2) 회원 조회
3) 회원 등록
4) 회원 수정
5) 회원 삭제
✅ API URI 설계
👉🏻 회원 목록 조회 /read-member-list
👉🏻 회원 조회 /read-member-by-id
👉🏻 회원 등록 /create-member
👉🏻 회원 수정 / update-member
👉🏻 회원 삭제 /delete-member
🤔 이것이 좋은 설계일까?
❗️ 가장 중요한 것은 리소스 식별
✅ API URI 고민
👉🏻 URI(Uniform Resource Identifier)
🤔 리소스의 의미는 뭘까?
❗️ 회원을 등록하고 수정, 조회하는 게 리소스가 아니라 회원 자체가 리소스임!
❗️ 그럼 어떻게 식별할래? 👉🏻 등록 / 수정 / 조회라는 행위를 배제하고 회원이라는 리소스만 식별 👉🏻 회원 리소스를 URI에 매핑
✅ API URI 설계
👉🏻 회원 목록 조회 /members
👉🏻 회원 조회 /members/{id} ❓ 어떻게 구분하지 ❓
👉🏻 회원 등록 /members/{id}❓ 어떻게 구분하지 ❓
👉🏻 회원 수정 /members/{id}❓ 어떻게 구분하지 ❓
👉🏻 회원 삭제 /members/{id} ❓ 어떻게 구분하지 ❓
🌟 리소스를 식별하고 URI 계층 구조를 활용해야 함!
🌟 리소스와 행위를 분리하자!
🌟 URI는 리소스만 식별
🌟 리소스와 해당 리소스를 대상으로 하는 행위를 분리
👉🏻 리소스는 회원 / 행위는 조회, 등록, 삭제, 변경
👉🏻 리소스는 명사 / 행위는 동사
📍 HTTP 메소드 - GET / POST
👉🏻 GET: 리소스 조회
👉🏻 POST: 요청 데이터 처리
👉🏻 PUT: 리소스 대체, 해당 리소스가 없으면 생성
👉🏻 PATCH: 리소스 부분 변경
👉🏻 DELETE: 리소스 삭제
✏️ 기타 메소드
👉🏻 HEAD: GET과 동일하지만 메시지 부분을 제외하고 상태 줄과 헤더만 반환
👉🏻 OPTIONS: 대상 리소스에 대한 통신 가능 옵션(메소드)을 주로 설명(CORS)에서 사용
👉🏻 CONNECT: 대상 자원으로 식별되는 서버에 대한 터널을 설정
👉🏻 TRACE: 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
✅ GET
GET /search?q=hello&hl=ko HTTP/1.1
Host:www.google.com👉🏻 리소스 조회
👉🏻 서버에 전달하고 싶은 데이터는 query(쿼리 파라미터, 쿼리 스트링) 통해 전달
👉🏻 메시지 바디를 사용해서 데이터를 전달할 수 있으나 지원하는 않는 곳이 많아서 권장하지 않음
리소스 조회 1️⃣ - 메시지 전달
리소스 조회 2️⃣ - JSON 등으로 서버 도착
리소스 조회 3️⃣ - 응답 데이터
✅ POST
POST /members HTTP/1.1
Content-Type: application/json
{
"username":"young",
"age":20
}👉🏻 요청 데이터 처리
👉🏻 메시지 바디를 통해 서버로 요청 데이터 전달
👉🏻 서버는 요청 데이터를 처리
👉🏻 메시지 바디를 통해 들어온 데이터를 처리하는 모든 기능 수행
👉🏻 주로 전달된 데이터로 신규 리소스 등록, 프로세스 처리에 사용
리소스 등록 1️⃣ - 메시지 전달
리소스 등록 2️⃣ - 신규 리소스 생성
/members/100
{
"username":"young",
"age":20
}리소스 등록 3️⃣ - 응답 데이터
HTTP/1.1 201 Created
Content-Type: application/json
Content-Length: 34
Location: /members/100
{
"username":"young",
"age":20
}
👉🏻 스펙: POST 메소드는 대상 리소스가 리소스의 고유한 의미 체계에 따라 요청에 포함된 표현을 처리하도록 요청
즉, HTML form에 입력한 정보로 회원가입하거나 주문할 때 사용 / 게시판 글 쓰기, 댓글 달기 / 신규 주문 생성 / 한 문서 끝에 내용 추가 등에 사용됨
👉🏻 이 리소스 URI에 POST 요청이 오면 요청 데이터를 어떻게 처리할지 리소스마다 따로 정해야 함! 정해진 것이 없음
1️⃣ 새 리소스 생성(등록): 서버가 아직 식별하지 않은 새 리소스 생성
2️⃣ 요청 데이터 처리: 단순 데이터 생성/변경을 넘어 프로세스 처리할 경우
👉🏻 주문 - 결재 완료 - 배달 시작 - 배달 완료처럼 프로세스가 변경되는 경우는 POST 사용해야 함!
👉🏻 POST의 결과로 새로운 리소스가 생성되지 않을 수도 있음
3️⃣ 다른 메소드로 처리하기 애매한 경우: JSON으로 넘겨야 하는데 GET을 사용하기 어려운 경우
📍 HTTP 메소드 - PUT / PATCH / DELETE
✅ PUT
PUT /members/100 HTTP/1.1
Content-Type: application/json
{
"username":"hello",
"age":20
}
👉🏻 리소스 있으면 완전 대체
PUT /members/100
// 기존 데이터
{
"username":"young",
"age":20
}
// 변경 데이터
{
"age":50
}
// 대체 데이터
{
"age":50
}
// -> 기존 리소스를 아예 덮어씌우므로 username도 없어짐👉🏻리소스 없으면 생성
👉🏻 덮어씌운다고 생각하면 편함 (동일 파일 이름 있으면 덮어씌우고, 없으면 새로 생성하는 것과 같은 원리)
⭐️ 클라이언트가 리소스 식별
👉🏻 클라이언트가 리소스 위치를 알고 URI 지정
👉🏻 POST와의 차이점: PUT은 클라이언트가 리소스의 전체 위치를 알고 지정함
✅ PATCH
PATCH /members/100
// 기존 데이터
{
"username":"young",
"age":20
}
// 변경 데이터
{
"age":50
}
// 대체 데이터
{
"username":"young",
"age":50
}
// -> 기존 리소스 중 일치하는 변경 데이터만 부분적으로 덮어씌움👉🏻 리소스 부분 변경
✅ DELETE
// 기존 데이터
{
"username":"young",
"age":20
}
Delelte /members/100
// 대체 데이터
// --> 사라짐👉🏻 리소스 제거
📍 HTTP 메소드의 속성
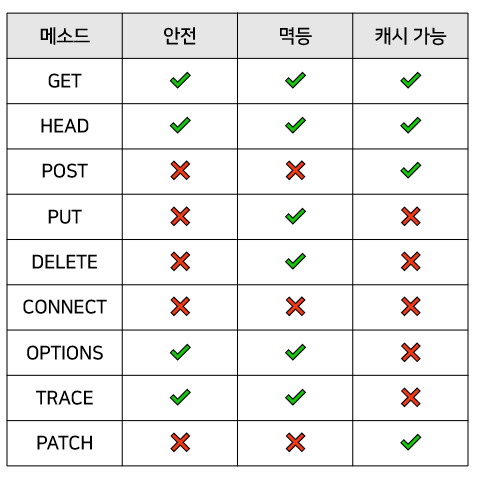
✅ 안전(Safe Methods)
👉🏻 호출해도 리소스를 변경하지 않음
👉🏻 GET은 단순 조회이므로 안전하다고 말할 수 있음
👉🏻 나머지 메소드는 변경이 일어나므로 안전하다고는 말할 수 없음
🤔 그래도 계속 호출해서 로그 같은 게 쌓여 장애 발생하면요?
🤷🏻♀️ 그건 안전이가 알 바 아니에요 그냥 리소스 변하냐 마냐만 볼 거예요
✅ 멱등(Idempotent)
👉🏻 한 번 호출하든 백 번 호출하든 결과가 같음
👉🏻 GET, PUT(기존 데이터를 '같은' 데이터로 덮음), DELETE(특정 리소스 여러 번 삭제해도 최종 삭제는 동일)는 멱등하다
👉🏻 POST는 멱등 아님! 두 번 호출하면 같은 결재가 중복하여 발생할 수도 있음
🤔 이게 왜 필요해요?
🤷🏻♀️ 자동 복구 메커니즘처럼, 서버가 timeout 등으로 정상 응답을 주지 못했을 때 클라이언트가 같은 요청을 다시 해도 되는지에 대한 판단 근거를 줘요
🤔 재요청 중간에 다른 곳에서 리소스를 변경하면요?
사용자1: GET -> name:A, age:20
사용자2: PUT -> name:A, age:30
사용자3: GET -> name:A, age:30 -> 사용자2 영향으로 바뀐 데이터가 조회되게 됨🤷🏻♀️ 그건 멱등이가 알 바 아니에요~ 멱등은 외부 요인으로 중간에 리소스가 변경되는 것까지는 고려하지 않아요
✅ 캐시 가능(Cachable)
👉🏻 응답 결과 리소스를 캐시해서 사용해도 되는가?
👉🏻 GET, HEAD, POST, PATCH 캐시 가능 ▶️ 실제로는 GET, HEAD 정도만 캐시로 사용함
👉🏻 POST, PATCH는 본문 내용까지 캐시 키로 고려해야 하는데 구현이 쉽지 않음