[Oracle] 02_DML(SELECT)_함수(Function)
02_DML(SELECT)_함수(Function)
함수(Function)
: 자바에서의 메소드와 같은 역할이라고 생각하면 됨
: 매개변수로 전달된 값들을 읽어서 내부적으로 계산한 결과를 리턴
: 하나의 큰 프로그램에서 반복적으로 사용되는 부분들을 분리하여 작성해 놓은 프로그램
: 호출하며 값을 전달하면 결과를 리턴하는 방식으로 사용
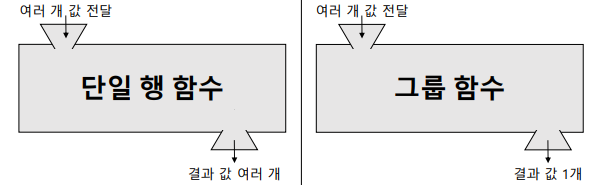
단일 행 함수: 한 줄씩, 한 행씩 결과물이 있음(매개변수가 n개라면 리턴값도 n개)
=> 매 행마다 함수 실행 후 매 행에 대한 결과를 모두 반환
그룹 함수: 한 뭉텅이를 전달하면 결과값이 1개로 축약되어 반환됨
=> 모든 행에 대해 하나의 그룹으로 묶어서 함수 실행 후 결과를 하나로 반환
*주의할 점: 단일행 함수와 그룹 함수는 함께 사용할 수 없음
애초에 결과의 행 개수가 다르게 나오기 때문!
<단일행 함수>
<문자열과 관련된 함수>
<LENGTH / LENGTHB>
- LENGTH(STR): 해당 전달된 문자열의 글자 수 반환
- LENGTHB(STR): 해당 전달된 문자열의 바이트 수 반환
결과값은 NUMBER 타입으로 반환
STR: '문자열' 리터럴/문자열 타입의 컬럼명
오라클에서의 문자 사이즈
숫자, 영문, 특수문자: '!', '~', 'A', 'a', '1', ... => 한 글자당 1BYTE로 취급
한글: 'ㄱ', '기', '김', 'ㅐ', ... => 한 글자당 3BYTE로 취급
SELECT LENGTH('오라클!'), LENGTHB('오라클!')
FROM DUAL; -- DUAL 테이블 == 가상 테이블 == DUMMY TABLE
-- 산술연산이나 가상 컬럼 등의 값을 단 한 번만 출력하고 싶을 때 FROM절에 작성하는 테이블명
SELECT EMAIL
, LENGTH(EMAIL)
, LENGTHB(EMAIL)
, EMP_NAME
, LENGTH(EMP_NAME)
, LENGTHB(EMP_NAME)
FROM EMPLOYEE;
<INSTR>
- INSTR(STR): 문자열로부터 특정 문자의 위치값을 반환
[ 표현법 ]
INSTR(STR, '특정문자', 찾을위치의시작값(생략가능), 순번(생략가능))
결과값은 NUMBER 타입으로 반환
찾을 위치의 시작값과 순번은 생략 가능
찾을 위치의 시작값
n : 앞에서 n번째에서부터 찾겠다 (생략 시 기본값 1)
-n : 뒤에서 n번째에서부터 찾겠다
=> ex) 3 기재 시 3번째(포함)부터 찾음
=> -n을 기재하더라도 앞에서부터 세서 돌려 주기 때문에 이 구문은 "찾을 범위"를 지정해 놓는 거라고 생각하면 쉬울 듯
SELECT INSTR('AABAACAABBAA', 'B')
FROM DUAL; -- 3: 찾고자 하는 위치, 몇 번째 해당 문자를 찾을 것인지에 대한 순번을 명시하지 않았음에도
-- 기본적으로 앞에서부터 첫 번째 글자의 위치를 찾아 주고 있음
SELECT INSTR('AABAACAABBAA', 'B', 1)
FROM DUAL; -- 3: 앞에서부터 첫 번째에 위치하는 B의 위치값을 알려 주겠음 (1부터 세기 시작함)
SELECT INSTR('AABAACAABBAA', 'B', -1)
FROM DUAL; -- 10: 뒤에서부터 첫 번째에 위치하는 B의 위치값을 알려 주겠음 (앞에서부터 세서 돌려줌)
SELECT INSTR('AABAACAABBAA', 'B', 1, 2)
FROM DUAL; -- 9: 앞에서부터 두 번째에 위치하는 B의 위치값을 알려 주겠음
SELECT INSTR('AABAACAABBAA', 'B', -1, 2)
FROM DUAL; -- 9: 뒤에서부터 두 번째에 위치하는 B의 위치값을 알려 주겠음
SELECT INSTR('AABAACAABBAA', 'E', 1, 1)
FROM DUAL; -- 0: 내가 찾고자 하는 값이 없을 경우 0을 반환해 줌
-- 실제 테이블에 적용해 보기
-- EMAIL에서 @의 위치를 찾아보자
SELECT EMAIL, INSTR(EMAIL, '@') AS "@의 위치"
FROM EMPLOYEE;
<SUBSTR>
- SUBSTR(STR, POSITION, LENGTH): 문자열로부터 특정 문자열을 추출해서 반환
(자바로 치면 문자열.substring() 메소드와 유사)
결과값은 CHARACTER 타입으로 반환(문자열 형태)
LENGTH는 생략 가능
- STR: '문자열' 리터럴 / 문자열 타입 컬럼명
- POSITION: 문자열을 추출할 시작 위치값 (음수도 제시 가능), POSITION번재 위치부터 추출
- LENGTH: 추출할 문자의 개수 (생략 시 끝까지 추출)
SELECT SUBSTR('SHOWMETHEMONEY', 7)
FROM DUAL; -- THEMONEY: 시작 위치는 1부터 시작해서 셈
SELECT SUBSTR('SHOWMETHEMONEY', 5, 2)
FROM DUAL; -- ME
SELECT SUBSTR('SHOWMETHEMONEY', 1, 6)
FROM DUAL; -- SHOWME
SELECT SUBSTR('SHOWMETHEMONEY', -8, 3)
FROM DUAL; -- THE: 시작 위치가 음수일 경우 뒤에서부터 N번째 위치로부터 문자를 추출하겠다는 뜻
-- 주민번호에서 성별 부분을 추출해서 남자(1), 여자(2)를 체크
SELECT EMP_NAME, EMP_NO, SUBSTR(EMP_NO, 8, 1) AS "성별"
FROM EMPLOYEE;
-- 남자 사원들의 사원명, 급여 조회
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
-- WHERE SUBSTR(EMP_NO, 8, 1) = '1' OR SUBSTR(EMP_NO, 8, 1) = '3';
WHERE SUBSTR(EMP_NO, 8, 1) IN ('1', '3');
-- 여자 사원들만 조회
SELECT EMP_NAME, SALARY
FROM EMPLOYEE
-- WHERE SUBSTR(EMP_NO, 8, 1) IN ('2', '4');
WHERE SUBSTR(EMP_NO, 8, 1) NOT IN ('1', '3');
-- EMAIL에서 ID부분만 추출해서 조회
SELECT EMP_NAME, EMAIL, SUBSTR(EMAIL, 1, INSTR(EMAIL, '@') - 1) "ID"
FROM EMPLOYEE;
<LPAD / RPAD>
- LPAD/RPAD(STR, 최종적으로반환할문자의길이(바이트), 덧붙이고자하는문자)
: 제시한 문자열에 임의의 문자열을 왼쪽(LPAD) 또는 오른쪽(RPAD)에 덧붙여서 최종 N 길이만큼의 문자열을 반환
결과값은 CHARACTER 타입으로 반환
덧붙이고자 하는 문자는 생략 가능
- STR: '문자열' 리터럴 / 문자열 타입의 컬럼명
SELECT LPAD(EMAIL, 16, ' ') -- 덧붙이고자 하는 문자 생략 시 기본값이 공백
FROM EMPLOYEE;
SELECT RPAD(EMAIL, 20, '#') -- 덧붙이고자 하는 문자 생략 시 기본값이 공백
FROM EMPLOYEE; -- bang_ms@kh.or.kr####
-- 850918-2******* 주민등록번호 조회 => 뒷 6자리가 노출되지 않도록 마스킹 후 보여 줄 것
-- 1단계. SUBSTR을 이용해서 주민번호 앞 8자리까지 추출
SELECT EMP_NAME, SUBSTR(EMP_NO, 1, 8)
FROM EMPLOYEE;
-- 2단계. RPAD를 중첩하여 주민번호 뒤 6자리에 *을 붙이기
SELECT EMP_NAME, RPAD(SUBSTR(EMP_NO, 1, 8), 14, '*')
FROM EMPLOYEE;
<LTRIM / RTRIM>
- LTRIM / RTRIM(STR, 제거시키고자하는문자)
: 문자열의 왼쪽 또는 오른쪽에서 제거시키고자 하는 문자들을 찾아서 제거한 나머지 문자열을 반환
결과값은 CHARACTER 타입으로 반환
제거시키고자 하는 문자는 생략 가능 (생략 시 기본값은 공백으로 설정됨)
- STR: '문자열' 리터럴 / 문자열 타입 컬럼명
SELECT LTRIM(' K H')
FROM DUAL; -- K H
SELECT RTRIM(' K H ')
FROM DUAL; -- K H
SELECT LTRIM('0001230456000', '0')
FROM DUAL; --1230456000
SELECT LTRIM('123123KH123', '123')
FROM DUAL; --KH123
SELECT LTRIM('ACABACCKH', 'ABC')
FROM DUAL; --KH
--> 제거시키고자 하는 문자열을 통으로 지워 주는 게 아니라 문자 하나하나로 비교해서 존재하면 다 지워 주는 원리
<TRIM>
- TRIM(BOTH/LEADING/TRAILING '제거시키고자하는문자' FROM STR)
: 문자열의 양쪽/앞쪽/뒤쪽에 있는 특정 문자를 제거한 나머지 문자열을 반환
결과값은 CHARACTER 타입으로 반환
BOTH/LEADING/TRAILING은 생략 가능! 단, 생략 시 기본값 BOTH
- STR: '문자열' 리터럴 / 문자열 타입 컬럼명
-- 참고: TRIM은 가운데에 있는 문자는 제거 못함 (REPLACE 활용)
SELECT TRIM(' K H ') -- BOTH ' ' FROM ' K H '과 같은 의미
FROM DUAL; -- K H
SELECT TRIM('Z' FROM 'ZZZKHZZZ')
FROM DUAL; -- KH
SELECT TRIM(LEADING 'Z' FROM 'ZZZKHZZZ') --- LEADING 앞쪽 제거( == LTRIM)
FROM DUAL; -- KHZZZ
SELECT TRIM(TRAILING 'Z' FROM 'ZZZKHZZZ') --- LEADING 앞쪽 제거( == LTRIM)
FROM DUAL; -- ZZZKH
<LOWER / UPPER / INITCAP>
- LOWER(STR): 다 소문자로 변경
- UPPER(STR): 다 대문자로 변셩
- INITCAP(STR): 띄어쓰기 기준으로 각 단어 앞글자만 대문자로 변경
결과값은 CHARACTER 타입으로 변경
- STR: '문자열' 리터럴 / 문자열 타입 컬럼명
SELECT LOWER('Welcome To My World!')
FROM DUAL;
SELECT UPPER('Welcome To My World!')
FROM DUAL;
SELECT INITCAP('Welcome To My World!')
FROM DUAL;
<CONCAT>
- CONCAT(STR1, STR2)
: 전달된 두 개의 문자열을 하나로 합친 결과를 반환
결과값은 CHARACTER 타입으로 반환
- STR1, STR2: '문자열' 리터럴 / 문자열 타입 컬럼
SELECT CONCAT('가나다', 'ABC')
FROM DUAL; -- 가나다ABC
SELECT '가나다' || 'ABC'
FROM DUAL; -- 가나다ABC
SELECT CONCAT('가나다', 'ABC', '123')
FROM DUAL;
--> 오류: CONCAT 함수는 한 번에 두 개의 문자열만 합치는 것이 가능
SELECT CONCAT(CONCAT('가나다', 'ABC'), '123')
FROM DUAL; -- 가나다ABC123
--> 만약 여러 개의 문자열을 합칠 때 CONCAT만 이용해야 한다면 중첩해서 사용 가능
<REPLACE>
- REPLACE(STR, 찾을문자, 바꿀문자)
: STR로부터 찾을 문자를 찾아서 바꿀 문자로 바꾼 문자열을 반환
결과값은 CHARACTER 타입으로 반환
- STR: '문자열' 리터럴 / 문자열 타입 컬럼
SELECT REPLACE('서울시 강남구 역삼동', '역삼동', '삼성동')
FROM DUAL; -- 서울시 강남구 삼성동
SELECT EMP_NAME, EMAIL, REPLACE(EMAIL, 'kh.or.kr', 'ioi.or.kr')
FROM EMPLOYEE;
-- 참고: TRIM은 가운데에 있는 문자는 제거 못함 (REPLACE 활용)
SELECT REPLACE(' K H ', ' ', '')
FROM DUAL; -- KH
<숫자와 관련된 함수>
<ABS>
- ABS(NUMBER): 절대값을 구해 주는 함수
SELECT ABS(-10)
FROM DUAL; -- 10
SELECT ABS(-10.9)
FROM DUAL; -- 10.9
<MOD>
- MODULER의 약자로 나머지를 구해 주는 함수
- MOD(NUMBER1, NUMBER2): 두 수를 나눈 나머지 값을 반환해 주는 함수
SELECT MOD(10, 3)
FROM DUAL; -- 1
SELECT MOD(-10, 3)
FROM DUAL; -- -1
SELECT MOD(-10.9, 3)
FROM DUAL; -- -1.9
<ROUND>
- ROUND(NUMBER, 위치값): 반올림 처리해 주는 함수
위치: 소수점 아래 N번째 수에서 반올림
위치값은 생략 가능! 단, 위치 생략 시 기본값은 0, 위치값은 음수로도 제시 가능
SELECT ROUND(123.456)
FROM DUAL; -- 123
SELECT ROUND(123.456, 1)
FROM DUAL; -- 123.5
SELECT ROUND(123.456, 2)
FROM DUAL; -- 123.46
SELECT ROUND(123.456, 3)
FROM DUAL; -- 123.456, 3번째까지 나타내야 하므로 본연의 값 그대로
SELECT ROUND(123.456, 4)
FROM DUAL; -- 123.456, 연산할 위치가 없으므로 본연의 값 그대로
SELECT ROUND(123.456, -1)
FROM DUAL; -- 120
SELECT ROUND(123.456, -2)
FROM DUAL; -- 100
<CEIL>
- CEIL(NUMBER): 소수점 아래의 수를 무조건 올림 처리 해 주는 함수
- 위치값 지정 불가!
SELECT CEIL(123.156)
FROM DUAL; -- 124
SELECT CEIL(249.012)
FROM DUAL; -- 250
<FLOOR>
- FLOOR(NUMBER): 소수점 아래의 수를 무조건 버림 처리 해 주는 함수
- 위치값 지정 불가!
SELECT FLOOR(123.956)
FROM DUAL; -- 123
SELECT FLOOR(207.68)
FROM DUAL; -- 207
-- 각 직원별로 고용일로부터 오늘까지 근무일수를 조회
-- 근무일수 = 오늘날짜 - 고용일
SELECT EMP_NAME, CONCAT(FLOOR(SYSDATE - HIRE_DATE), '일') AS "근무일수"
FROM EMPLOYEE;
<TRUNC>
- TRUNC(NUMBER, 위치값): 위치 지정 가능한 버림 처리를 해 주는 함수
위치값 생략 가능! 단, 생략 시 기본값은 0 (== FLOOR 함수와 같은 역할)
SELECT TRUNC(123.756)
FROM DUAL; -- 123
SELECT TRUNC(123.756, 1)
FROM DUAL; -- 123.7
SELECT TRUNC(123.756, -1)
FROM DUAL; -- 120
<날짜 관련 함수>
DATE 타입을 다루는 함수들
DATE타입: "년, 월, 일, 시, 분, 초"를 다 포함한 자료형
-- SYSDATE: 현재 이 DB가 깔려 있는 컴퓨터 시스템 설정상의 날짜
SELECT SYSDATE
FROM DUAL; -- 22/08/24 형식으로 출력(날짜로써)
SELECT '22/08/24'
FROM DUAL; -- 22/08/24 형식으로 출력(문자열로써)
-- MONTHS_BETWEEN(DATE1, DATE2): 두 날짜 사이의 개월 수를 반환해 주는 함수
-- 각 직원별로 고용일로부터 오늘까지의 근무 일 수와 근무 개월 수를 조회
SELECT EMP_NAME
, FLOOR(SYSDATE - HIRE_DATE) || '일' AS "근무일수"
, FLOOR(MONTHS_BETWEEN(SYSDATE, HIRE_DATE)) || '개월' AS "근무개월수"
FROM EMPLOYEE;
--> 두 날짜 사이의 개월 수를 숫자 타입으로 반환해 주되,
-- 첫 번째 매개변수에 해당되는 DATE1 부분이 더 과거일 경우 음수로 결과가 나옴!
-- ADD_MONTHS(DATE, NUMBER): 특정 날짜에 해당 숫자만큼의 개월 수를 더한 날짜를 반환해 주는 메소드 (DATE 타입 반환)
-- 오늘 날짜로부터 5개월 후
SELECT ADD_MONTHS(SYSDATE, 5)
FROM DUAL;
-- 오늘 날짜로부터 1개월 전(음수 제시 가능)
SELECT ADD_MONTHS(SYSDATE, -1)
FROM DUAL;
-- 전체 사원들의 직원명, 입사일, 입사 후 6개월이 흘렀을 때의 날짜
SELECT EMP_NAME, HIRE_DATE, ADD_MONTHS(HIRE_DATE, 6) AS "입사 후 6개월"
FROM EMPLOYEE;
-- NEXT_DAY(DATE, 요일(문자/숫자)): 특정 날짜에서 가장 가까운 해당 요일을 찾아서 그 날짜를 반환
SELECT NEXT_DAY(SYSDATE, '일요일')
FROM DUAL; -- 22/08/28
SELECT NEXT_DAY(SYSDATE, '일')
FROM DUAL; -- 22/08/28
-- 1: 일요일, 2: 월요일, 3: 화요일, ... , 6: 금요일, 7: 토요일
SELECT NEXT_DAY(SYSDATE, 1)
FROM DUAL; -- 22/08/28
-- 현재 이 시스템에 설정된 언어가 KOREAN이기 때문에 오류가 발생
SELECT NEXT_DAY(SYSDATE, 'SUNDAY')
FROM DUAL;
-- 언어 변경
ALTER SESSION SET NLS_LANGUAGE = AMERICAN;
SELECT NEXT_DAY(SYSDATE, 'SUNDAY')
FROM DUAL;
SELECT NEXT_DAY(SYSDATE, '일')
FROM DUAL; -- 22/08/28
ALTER SESSION SET NLS_LANGUAGE = KOREAN;
SELECT NEXT_DAY(SYSDATE, '일')
FROM DUAL; -- 22/08/28
-- LAST_DAY(DATE): 해당 특정 날짜 달의 마지막 날짜를 구해서 반환해 주는 함수 (DATE 타입 반환)
SELECT LAST_DAY(SYSDATE)
FROM DUAL;
-- 직원명, 입사일, 입사한 달의 마지막 날짜 조회
SELECT EMP_NAME, HIRE_DATE, LAST_DAY(HIRE_DATE)
FROM EMPLOYEE;
<EXTRACT>
: 년도 또는 월 또는 일 정보만 추출해서 변환(NUMBER 타입 반환)
- EXTRACT(YEAR FROM DATE): 특정 날짜로부터 년도만 추출
- EXTRACT(MONTH FROM DATE): 특정 날짜로부터 월만 추출
- EXTRACT(DAY FROM DATE): 특정 날짜로부터 일만 추출
SELECT EXTRACT(YEAR FROM SYSDATE) -- 오늘 날짜 기준 년도 추출
, EXTRACT(MONTH FROM SYSDATE) -- 오늘 날짜 기준 월 추출
, EXTRACT(DAY FROM SYSDATE) -- 오늘 날짜 기준 일 추출
FROM DUAL;
-- 사원명, 입사년도, 입사월, 입사일 조회
SELECT EMP_NAME
, EXTRACT(YEAR FROM HIRE_DATE) || '년' AS "입사년도"
, EXTRACT(MONTH FROM HIRE_DATE) || '월' AS "입사월"
, EXTRACT(DAY FROM HIRE_DATE) || '일' AS "입사일"
FROM EMPLOYEE
ORDER BY "입사년도", "입사월", "입사일";
<형변환 함수>
<NUMBER/DATE => CHARACTER>
-TO_CHAR(NUMBER/DATE, '포맷')
: 숫자형 또는 날짜형 데이터를 문자형 타입으로 변환 (CHARACTER 타입 반환)
SELECT TO_CHAR(1234)
FROM DUAL; -- 1234 (숫자) => '1234' (문자열)
SELECT TO_CHAR(1234, '00000')
FROM DUAL; -- 1234 (숫자) => '01234' (문자열): 빈칸을 0으로 채워 주는 포맷
SELECT TO_CHAR(1234, '99999')
FROM DUAL; -- 1234 (숫자) => '1234' (문자열): 빈칸을 채우지 않는 포맷
SELECT TO_CHAR(1234, 'L00000')
FROM DUAL; -- 1234 (숫자) => \01234 (문자열): 현재 설정된 지역(LOCAL)의 화폐 단위를 붙여 주는 포맷
SELECT TO_CHAR(1234, 'L99999')
FROM DUAL; -- 1234 (숫자) => \1234 (문자열)
-- 만약에 달러로 표현하고 싶다면?
SELECT TO_CHAR(1234, '$99999')
FROM DUAL; -- 1234 (숫자) => $1234 (문자열)
-- 금액과 같은 큰 숫자의 경우 3자리마다 ,로 구문해서 출력
SELECT TO_CHAR(1234, 'L99,999')
FROM DUAL; -- 1234 (숫자) => \1,234 (문자열): 3자리마다 ,로 구분해 주는 포맷
-- 급여 정보를 3자리마다 ,로 구분하여 출력
SELECT EMP_NAME, TO_CHAR(SALARY, 'L999,999,999') "급여정보"
FROM EMPLOYEE
ORDER BY 급여정보;
-- DATE(년월일시분초) => CHARACTER
SELECT SYSDATE
FROM DUAL;
SELECT TO_CHAR(SYSDATE)
FROM DUAL; -- '22/08/24' (문자열)
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD')
FROM DUAL; -- '2022-08-24'
SELECT TO_CHAR(SYSDATE, 'AM HH:MI:SS') -- AM 또는 PM: 오전/오후 판별해서 출력하라는 의미이지, AM이라고 오전, PM이라고 오후 고정 개념이 아님!
FROM DUAL; -- '오후 03:39:26'
SELECT TO_CHAR(SYSDATE, 'HH24:MI:SS')
FROM DUAL; -- '15:41:51'
SELECT TO_CHAR(SYSDATE, 'MON DY, YYYY') -- MON: N월, DY: '요일'을 뺀 형태의 요일
FROM DUAL; -- '8월 수, 2022'
-- 년도로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'YYYY') -- 2022
, TO_CHAR(SYSDATE, 'RRRR') -- 2022
, TO_CHAR(SYSDATE, 'YY') -- 22
, TO_CHAR(SYSDATE, 'RR') -- 22
, TO_CHAR(SYSDATE, 'YEAR') -- TWENTY TWENTY-TWO
FROM DUAL;
-- 월로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'MM') -- 08
, TO_CHAR(SYSDATE, 'MON') -- 8월
, TO_CHAR(SYSDATE, 'MONTH') -- 8월
, TO_CHAR(SYSDATE, 'RM') -- VIII, 로마 숫자로 월을 출력해 주는 포맷
FROM DUAL;
-- 일로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'D') -- 4, 1주일 기준으로 (일요일부터) 며칠이 흘렀는지 알려 주는 포맷
, TO_CHAR(SYSDATE, 'DD') -- 24, 1달 기준으로 (해당 달의 1일부터) 며칠이 흘렀는지 반환해 주는 포맷
, TO_CHAR(SYSDATE, 'DDD') -- 236, 1년 기준으로 (해당 년도의 1월 1일부터) 며칠이 흘렀는지 반환해 주는 포맷
FROM DUAL;
-- 요일로써 쓸 수 있는 포맷
SELECT TO_CHAR(SYSDATE, 'DY') -- 수, DY에는 '요일'을 뺀 형식으로 출력해 주는 포맷
, TO_CHAR(SYSDATE, 'DAY') -- 수요일, DAY는 '요일'을 붙인 형식으로 출력해 주는 포맷
FROM DUAL;
-- 2022년 08월 24일 (수) 포맷으로 적용시키고 싶음
SELECT TO_CHAR(SYSDATE, 'YYYY"년" MM"월" DD"일" "("DY")"')
FROM DUAL; -- 포맷이 아닌 다른 문자랑 같이 쓰고자 할 경우 ""로 묶어 줌
-- 사원명, 입사일(위의 포맷 적용) 조회
SELECT EMP_NAME, TO_CHAR(HIRE_DATE, 'YYYY"년" MM"월" DD"일" "("DY")"') AS "입사일"
FROM EMPLOYEE;
-- 2010년 이후에 입사한 사원들의 사원명, 입사일(위의 포맷 적용) 조회
SELECT EMP_NAME, TO_CHAR(HIRE_DATE, 'YYYY"년" MM"월" DD"일" "("DY")" ') AS "입사일"
FROM EMPLOYEE
WHERE EXTRACT(YEAR FROM HIRE_DATE) >= 2010;
<NUMBER/CHARACTER => DATE>
- TO_DATE(NUMBER/CHARACTER, '포맷'): 숫자형 또는 문자형 데이터를 날짜형으로 변환해 주는 함수 (DATE 타입 반환)
SELECT TO_DATE(20210101)
FROM DUAL; -- 기본 포맷은 YY/MM/DD로 변환됨
SELECT TO_DATE('20210101')
FROM DUAL; -- YY/MM/DD
-- 주의할 점: 매개변수로 NUMBER 타입을 넘길 경우 0으로 시작하는 년도는 반드시 문자열 타입으로 넘겨 줘야 함
SELECT TO_DATE(000101) -- 000101은 0으로 시작하는 숫자로 인식하여 에러 발생
FROM DUAL;
SELECT TO_DATE('000101')
FROM DUAL; -- YY/MM/DD
SELECT TO_DATE('20100101', 'YYYYMMDD')
FROM DUAL; -- YY/MM/DD 형식으로 나옴 (값 보기 버튼 눌러보기)
SELECT TO_DATE('041030 143021', 'YYMMDD HH24MISS')
FROM DUAL; -- YY/MM/DD 형식으로 나옴
-- 주의할 점: YY와 RR의 차이점
SELECT TO_DATE('140630', 'YYMMDD')
FROM DUAL; -- 2014년도
SELECT TO_DATE('980630', 'YYMMDD')
FROM DUAL; -- 2098년도
-- TO_DATE 함수를 이용해서 DATE 형식으로 변환 시
-- 두 자리 년도에 대해 YY 포맷을 적용할 경우 => 무조건 현재 세기
SELECT TO_DATE('140630', 'RRMMDD')
FROM DUAL; -- 2014년도
SELECT TO_DATE('980630', 'RRMMDD')
FROM DUAL; -- 1998년도
-- TO_DATE 함수를 이용해서 DATE 형식으로 변환 시
-- 두 자리 년도에 대해 RR 포맷을 적용할 경우 => 50 이상이면 이전 세기, 50 미만이면 현재 세기로
<CHARACTER => NUMBER>
- TO_NUMBER(CHARACTER, '포맷'): 문자형 데이터를 숫자형으로 변환 (NUMBER 타입 반환)
-- 자동형변환 되는 예시
SELECT '123' + '123'
FROM DUAL; -- 246: 자동형변환 후 산술연산까지 진행
-- 자동형변환이 안 되는 예시
SELECT '10,000,000' + '550,000'
FROM DUAL; -- 문자(,)가 포함되어 있기 때문에 자동형변환이 안 됨
--> 이런 경우에 사용할 수 있는 함수가 TO_NUMBER
-- 위의 예시를 TO_NUMBER 함수를 이용하여 변경 => 강제형변환
SELECT TO_NUMBER('10,000,000', '99,999,999') + TO_NUMBER('550,000', '999,999')
FROM DUAL; -- 10550000
-- 만약 위의 결과를 10,550,000 이렇게 보고 싶다면?
SELECT TO_CHAR(TO_NUMBER('10,000,000', '99,999,999') + TO_NUMBER('550,000', '999,999'), '99,999,999')
FROM DUAL; -- 10,550,000
-- 0123?
SELECT TO_NUMBER('0123')
FROM DUAL; -- 123
<NULL 처리 함수>
-- NVL(컬럼명, 해당컬럼값이NULL일경우반환할결과값)
: 해당 컬럼값이 존재할 경우 기존의 컬럼값을 그대로 반환, 해당 컬럼값이 NULL일 경우 내가 제시한 결과값을 반환
-- 사원명, 보너스, 보너스가 없는 경우 0으로 출력
SELECT EMP_NAME, BONUS, NVL(BONUS, 0)
FROM EMPLOYEE;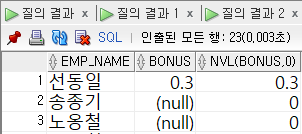
-- 보너스 포함 연봉을 조회
-- SELECT EMP_NAME, NVL((SALARY + (SALARY * BONUS)) * 12, SALARY * 12)
SELECT EMP_NAME, (SALARY + (SALARY * NVL(BONUS, 0))) * 12
FROM EMPLOYEE;
-- 사원명, 부서코드(부서코드가 없는 경우 '없음') 조회
SELECT EMP_NAME, NVL(DEPT_CODE, '없음')
FROM EMPLOYEE;
-- NLV2(컬럼명, 결과값1, 결과값2)
: 해당 컬럼값이 존재할 경우 결과값1을 반환, 해당 컬럼값이 NULL일 경우 결과값2를 반환
-- 사원명, 보너스, 보너스가 있는 경우 0.7로 인상, 보너스가 없는 경우 0 출력
SELECT EMP_NAME, BONUS, NVL2(BONUS, 0.7, 0)
FROM EMPLOYEE;
-- 사원명, 부서코드(부서코드가 있는 경우 '부서배치완료', 없는 경우 '부서배치미완료') 조회
SELECT EMP_NAME, DEPT_CODE, NVL2(DEPT_CODE, '부서배치완료', '부서배치미완료')
FROM EMPLOYEE;
-- NULLIF(비교대상1, 비교대상2)
: 두 매개변수의 값이 일치할 경우 NULL 반환, 두 매개변수의 값이 일치하지 않을 경우 비교대상1 반환
SELECT NULLIF('123', '123')
FROM DUAL; -- (NULL)
SELECT NULLIF('123', '456')
FROM DUAL; -- 123<선택 함수>
DECODE(비교대상(컬럼명/산술연산/함수식), 조건값1, 결과값1, 조건값2, 결과값2, ..., 결과값)
- 자바에서의 SWITCH문과 유사 (동등비교를 해 주는 조건문)
switch(비교대상) {
case 조건값1 : 결과값1; break;
case 조건값2 : 결과값2; break;
...
default : 결과값;
}
-- 사번, 사원명, 성별(주민등록번호로부터 성별 자리를 추출)
SELECT EMP_ID, EMP_NAME, DECODE(SUBSTR(EMP_NO, 8, 1), '1', '남'
, '2' ,'여'
, '3', '남'
, '4', '여') "성별"
FROM EMPLOYEE;
-- 직원들의 급여를 인상시켜서 조회
-- 직급코드가 'J7'인 사원은 급여를 10% 인상해서 조회
-- 직급코드가 'J6'인 사원은 급여를 15% 인상해서 조회
-- 직급코드가 'J5'인 사원은 급여를 20% 인상해서 조회
-- 그 이외의 직급코드인 사원은 급여를 5% 인상해서 조회
SELECT EMP_NAME, JOB_CODE, SALARY, DECODE(JOB_CODE, 'J7', SALARY * 1.1
, 'J6', SALARY * 1.15
, 'J5', SALARY * 1.2
, SALARY * 1.05) "인상된급여"
FROM EMPLOYEE;
<CASE WHEN THEN 구문>
-- DECODE 선택함수와 비교하면 DECODE는 해당 조건 검사 시 동등비교만을 수행한다면
CASE WHEN THEN 구문은 특정 조건 제시 시 내 마음대로 조건식을 기술 가능
- 자바에서의 if-else if문 같은 느낌
if(조건식1) {
실행할구문;
}
else if(조건식2) {
실행할구문;
} else {
실행할구문;
}
[ 표현법 ]
CASE WHEN 조건식1 THEN 결과값1
WHEN 조건식2 THEN 결과값2
...
ELSE 결과값
END
-- 사번, 사원명, 주민번호로부터 추출한 성별(DECODE함수)
SELECT EMP_ID
, EMP_NAME
, DECODE(SUBSTR(EMP_NO, 8,1), '1', '남'
, '2', '여'
, '3', '남'
, '4', '여') "성별"
FROM EMPLOYEE;
-- CASE WHEN THEN 구문 버전
SELECT EMP_ID
, EMP_NAME
, CASE WHEN SUBSTR(EMP_NO, 8,1) = '1' THEN '남'
WHEN SUBSTR(EMP_NO, 8,1) = '2' THEN '여'
WHEN SUBSTR(EMP_NO, 8,1) = '3' THEN '남'
WHEN SUBSTR(EMP_NO, 8,1) = '4' THEN '여'
END "성별"
FROM EMPLOYEE;
-- 경우의 수를 줄여 보기
SELECT EMP_ID
, EMP_NAME
, CASE WHEN SUBSTR(EMP_NO, 8,1) = '1' OR SUBSTR(EMP_NO, 8,1) = '3' THEN '남'
WHEN SUBSTR(EMP_NO, 8,1) = '2' OR SUBSTR(EMP_NO, 8,1) = '4' THEN '여'
END "성별"
FROM EMPLOYEE;
-- 경우의 수를 줄여 보기 (IN 사용해 보기)
SELECT EMP_ID
, EMP_NAME
, CASE WHEN SUBSTR(EMP_NO, 8,1) IN ('1', '3') THEN '남'
WHEN SUBSTR(EMP_NO, 8,1) IN ('2', '4') THEN '여'
END "성별"
FROM EMPLOYEE;
-- 경우의 수를 줄여 보기
SELECT EMP_ID
, EMP_NAME
, CASE WHEN SUBSTR(EMP_NO, 8,1) IN ('1' , '3') THEN '남'
ELSE '여'
END "성별"
FROM EMPLOYEE;
-- 사원명, 급여, 급여등급 (고급, 중급, 초급)
-- SALARY 값이 500만원 초과일 경우 '고급'
-- 500만원 이하 350만원 초과일 경우 '중급'
-- 350만원 이하일 경우 '초급'
SELECT EMP_NAME
, SALARY
, CASE WHEN SALARY > 5000000 THEN '고급'
WHEN SALARY > 3500000 THEN '중급'
ELSE '초급'
END "급여등급"
FROM EMPLOYEE
WHERE SALARY > 5000000 -- 고급만 보겠다
ORDER BY SALARY DESC; -- 월급이 높은 순서대로 보겠다
<그룹 함수>
그룹 함수: n개의 값을 읽어서 1개의 결과를 반환 (하나의 그룹별로 함수 실행 결과 반환)
-- 1. SUM(숫자타입컬럼명): 해당 컬럼값들의 총 합계를 구해서 반환해 주는 함수 (NUMBER 타입 변환)
-- 전체 사원들의 총 급여 합계
SELECT SUM(SALARY)
FROM EMPLOYEE;
-- 부서 코드가 'D5'인 사원들의 총 급여 합계
SELECT SUM(SALARY)
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5';
-- 남자 사원의 총 급여 합
SELECT SUM(SALARY)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8, 1) IN('1', '3');
-- 2. AVG(숫자타입컬럼명): 해당 컬럼값들의 평균값을 구해서 반환해 주는 함수 (NUMBER 타입 변환)
-- 전체 사원들의 평균 급여
SELECT AVG(SALARY)
FROM EMPLOYEE;
-- 전체 사원들의 평균 급여(반올림)
SELECT ROUND(AVG(SALARY))
FROM EMPLOYEE;
-- 3. MIN(아무타입컬럼명): 해당 컬럼값들 중 가장 작은 값을 반환해 주는 함수(매개변수의 타입을 반환)
-- 전체 사원들 중 최저급여, 가장 작은 이름값, 가장 작은 이메일값, 가장 예전에 입사한 날짜 구하기
SELECT MIN(SALARY) "최저급여"
, MIN(EMP_NAME) "가장작은이름"
, MIN(EMAIL) "가장작은이메일"
, MIN(HIRE_DATE) "가장작은입사일"
FROM EMPLOYEE;
SELECT *
FROM EMPLOYEE
ORDER BY HIRE_DATE ASC; -- 가장예전입사일 ~ 가장최근입사일 순서로 출력됨
--> MIN 함수의 원리: 해당 컬럼값을 기준으로 오름차순 정렬했을 때 가장 위쪽에 나오는 값이 리턴
-- 4. MAX(아무타입컬럼명): 해당 컬럼값들 중 가장 큰 값을 반환해 주는 함수(매개변수의 타입을 반환)
-- 전체 사원들 중 최고급여, 가장 큰 이름값, 가장 큰 이메일값, 가장 최근 입사일 구하기
SELECT MAX(SALARY) "최고급여"
, MAX(EMP_NAME) "가장큰이름값"
, MAX(EMAIL) "가장큰이메일값"
, MAX(HIRE_DATE) "가장큰입사일"
FROM EMPLOYEE;
SELECT *
FROM EMPLOYEE
ORDER BY EMP_NAME DESC;
--> MAX 함수의 원리: 해당 컬럼값을 기준으로 내림차순 정렬했을 때 가장 위쪽에 나오는 값이 리턴
-- 5. COUNT(*/컬럼명/DISTINCT 컬럼명): 조회된 행의 개수를 반환해 주는 함수(NUMBER 타입 반환)
-- COUNT(*): 조회 결과에 해당되는 모든 행 개수를 다 세서 반환
-- COUNT(컬럼명): 제시한 해당 컬럼값이 NULL이 아닌 것만 행 개수를 세서 반환
-- COUNT(DISTINCT 컬럼명): 제시한 해당 컬럼값이 중복값이 있을 경우 한 개로만 개수를 세서 반환 (NULL 포함 X)
-- 전체 사원 수 조회
SELECT COUNT(*)
FROM EMPLOYEE;
-- 여자 사원 수 조회
SELECT COUNT(*)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8, 1) IN('2', '4');
-- 부서 배치가 된 사원(DEPT_CODE 값이 존재) 수
-- 방법 1) 전체 수를 카운트하고 NULL 값을 카운트에서 빼는 방법
SELECT COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL;
-- 방법 2) 애초에 카운트 시 NUILL만 빼고 카운트하는 방법
SELECT COUNT(DEPT_CODE)
FROM EMPLOYEE;
-- 부서 배치가 된 사원(DEPT_CODE 값이 존재) 여자 사원 수
-- 방법 1)
SELECT COUNT(*)
FROM EMPLOYEE
WHERE DEPT_CODE IS NOT NULL
AND SUBSTR(EMP_NO, 8, 1) IN ('2', '4');
-- 방법 2)
SELECT COUNT(DEPT_CODE)
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, 8, 1) IN ('2', '4');
-- 사수가 있는 사원 수
SELECT COUNT(MANAGER_ID)
FROM EMPLOYEE;
-- 현재 사원들이 속해 있는 부서의 개수
SELECT COUNT(*)
FROM DEPARTMENT; -- 9
--> 사람들이 속해 있지 않은 부서까지 함께 출력함 // 요구사항 지키지 못했음
SELECT COUNT(DISTINCT DEPT_CODE)
FROM EMPLOYEE; -- 6 (사원들이 한 명이라도 있는 부서의 개수) <그룹 함수>